智能问数指的是对结构化数据(数据库、Excel)的数据智能查询。
在大模型出现之前,有些BI系统通过预定义数据集、字段别名、同义词、规则模板(槽填充),把自然语言映射到字段、筛选、排序、聚合,从而实现一定程度的自助问数。
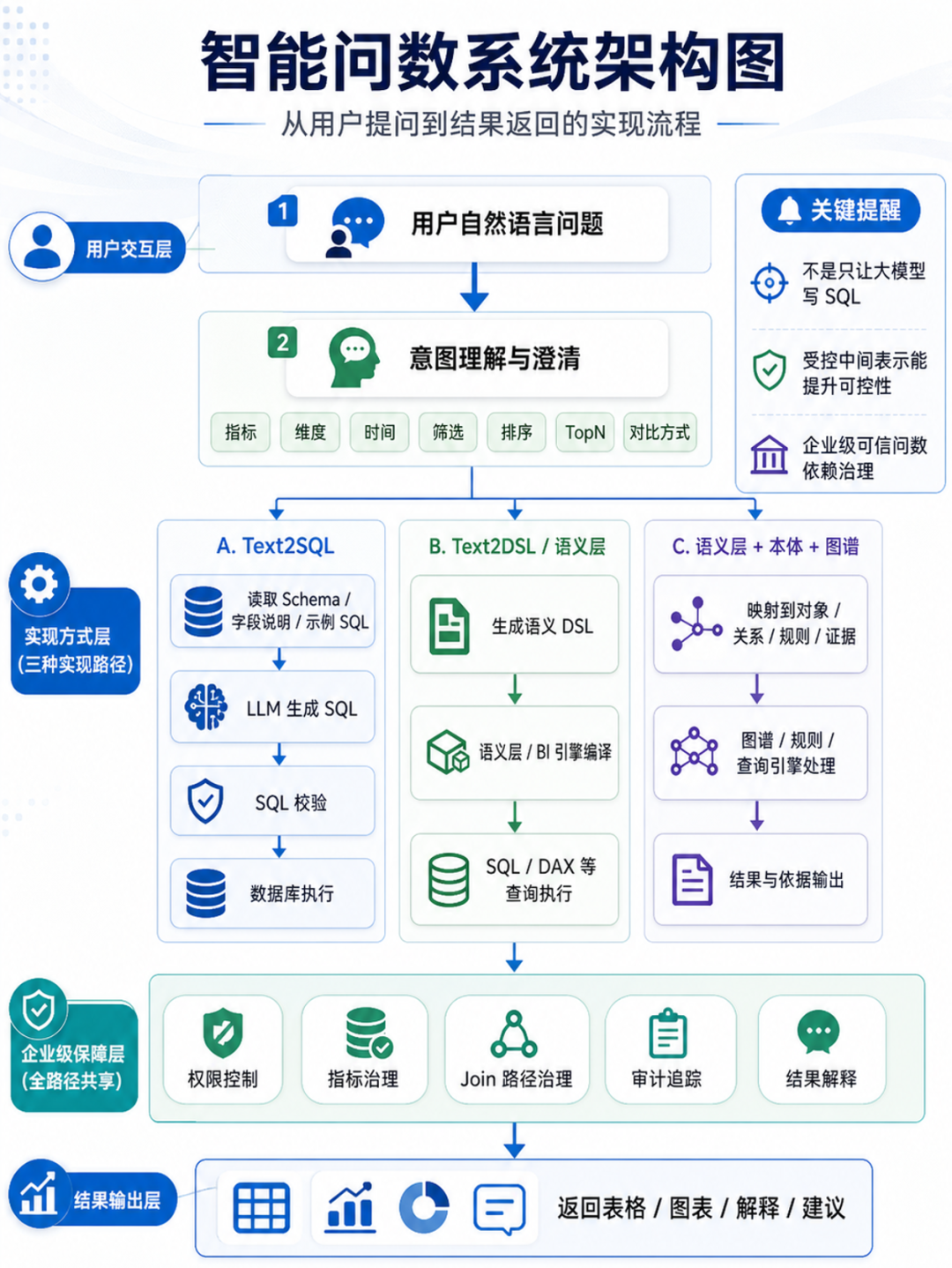
大模型出现后,基于大模型的能力生成IR或SQL成为智能问数的重要技术方向。当前主流的智能问数有下面几个技术路线:
路线1:Text2SQL
大量希望借助大模型探索智能问数的团队,都会天然采用这种技术路线。
用户问题
→ 读取 schema / 样例 SQL / 字段说明
→ LLM 生成 SQL
→ SQL 校验
→ 数据库执行
→ 返回表格/图表在单表、小宽表、字段含义清晰、口径简单的场景中,Text2SQL 往往只需要 schema、字段描述、样例数据和少量 SQL 示例即可启动。技术流程很直观,最能体现大模型能力的直接使用。langchain、dify的文档中,也提供了这种路线的案例。
对于单表 / 小宽表问数的简单场景,这个路线是合适的,实现也是最快的;此外,如果是数据开发、分析师使用,由于用户本身对底层数据非常清楚,使用也没问题。但是如果场景稍微复杂一点,很快就到很多问题。
Text2SQL特点:
| 维度 | 表现 |
|---|---|
| 优点 | 接入快,适合原型和结构化数据 |
| 缺点 | 对 schema 质量、样例 SQL、校验要求高 |
| 适合 | 数据结构清晰、表少、口径简单的场景 |
| 核心风险 | SQL 幻觉、join 错误、指标口径错误 |
路线2:Text2DSL / Text2Semantic 路线
对追求可信、可治理、可复用指标口径的企业级问数,Text2DSL / 语义层路线正在成为更稳妥的主流架构。
Text2DSL不是让大模型直接写 SQL,而是让它先生成一个更受控的中间表示(IR),比如:
用户问题
→ 意图解析
→ 指标 / 维度 / 时间 / 筛选 / 排序 / TopN / 对比方式
→ 语义查询 DSL
→ BI 引擎或语义层生成 SQL / DAX / LookML Query / SemQL
→ 执行
→ 结果解释Text2DSL主要解决的是业务概念的澄清(指向性)和约束问题。例如销售部门、运营部门、财务部门内部问数:
本月 GMV 是多少?(GMV是什么)
新客转化率是多少?(什么是新客、什么是转化率、什么是新客转化率)
各渠道 ROI 怎么样?
哪些产品销售额下降最多?(销售额使用那个指标)
这类场景通常需要语义层(而且对于业务域也基本够用),因为涉及:
- 指标定义
- 维度定义
- 时间口径
- 聚合规则
- 常用过滤条件
- join 路径
此外,之前很多做数据治理的公司,有较好的数仓模型,比如:
- 事实表
- 维度表
- 主题域
- 指标体系
- 统一维度编码
这个时候也很适合使用语义层,因为很多对象关系已经体现在数仓模型里:
- 订单事实表关联客户维表;
- 销售事实表关联产品维表;
- 财务事实表关联组织维表;
- 时间、区域、渠道有标准维表。
需要说明,现在也有专门的语义层产品或项目,例如cube(智能时代,企业的可信数据底座怎么建)。
Text2DSL特点:
| 维度 | 表现 |
|---|---|
| 优点 | 更可控、更可解释、更适合企业级 |
| 缺点 | 需要建设语义层、指标层、对象层 |
| 适合 | 复杂指标、复杂业务口径、多部门共用 |
| 核心壁垒 | 语义层、指标治理、DSL、查询编译器 |
路线3:语义层 + 本体 + 图谱
当问数从单一业务域进入跨部门、跨系统、对象关系复杂、需要归因解释或需要结合文档证据的场景时,仅有指标语义层往往不够,还需要引入本体和图谱能力。语义层负责“指标如何计算”,本体图谱负责“对象是谁、关系是什么、上下文和证据是什么”。
典型结构:
业务对象 / 指标 / 维度 / 关系 / 规则 / 知识
→ 本体/语义层/知识图谱
→ LLM 只负责理解意图
→ 查询和计算交给确定性引擎指标语义层:回答“怎么算”
对象本体层:回答“谁是谁、关系是什么”
上下文/证据层:回答“为什么、依据来自哪里、当前状态是什么”
本体+图谱的技术路线,不是简单地让大模型“多知道一些业务知识”,而是把企业中的核心对象、对象关系、指标口径、业务规则、状态事件和证据来源显式建模。LLM 主要负责理解用户意图,并将问题映射到受治理的对象、指标和关系上;真正的查询、计算、推理和溯源,则交给语义层、图谱引擎、查询引擎或规则引擎完成。这条路线适合跨部门、跨系统、对象关系复杂、需要消歧、归因解释或证据溯源的企业级问数场景。它的建设成本更高,但可信度、可解释性和可扩展性也更强。
需要说明,路线2和路线3对企业的数据治理提出了要求,但也正因为对数据做了治理,所以才可能实现可信数据查询。去年美国AI行业发生了多起对数据治理公司的收购,即是企业开始意识到agent落地过程中首先需要进行数据治理(企业可信数据底座架构与厂家梳理)。
特点:
| 维度 | 表现 |
|---|---|
| 优点 | 适合企业级可信问数 |
| 缺点 | 建模成本高,需要治理能力 |
| 适合 | 大企业、多系统、多指标、多对象场景 |
| 核心壁垒 | 企业对象层、语义模型、图谱、指标治理 |
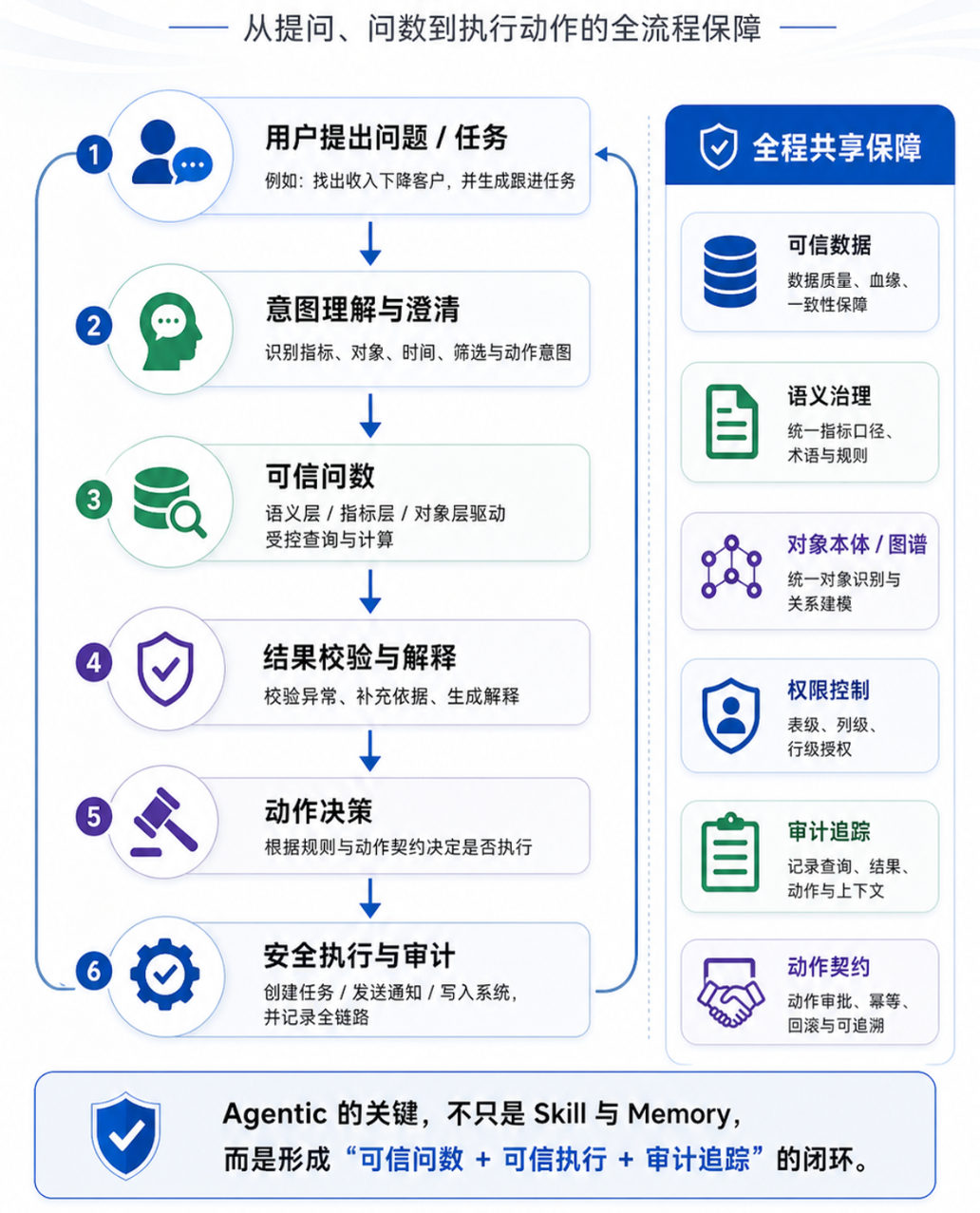
Agentic趋势
上面的路线是基本的智能问数技术,智能问数系统现在正在向Agentic(问数后还要行动)方向发展。例如用户问:
找出本月收入下降最严重的客户,并生成跟进任务。
发现库存异常后通知供应链负责人。
如果某指标连续三天下降,自动生成分析报告和整改建议。
这时智能问数不只是回答,而是进入执行。这其实也是一种最近红杉资本、黄仁勋提到的市场价值巨大的AI服务。
但是要让Agentic准确执行,系统必须清楚知道:
- 指标是否真的异常;
- 异常影响哪些对象;
- 相关负责人是谁;
- 应该触发什么动作;
- 动作会影响哪些系统;
- 结论依据是什么。
因此,这种场景通常需要有:
- 语义层:保证指标计算正确;
- 本体 / 图谱:保证对象识别正确;
- 状态图谱:保证当前上下文正确;
- 动作契约:保证执行动作正确;
- 审计链路:保证可追溯。
结语
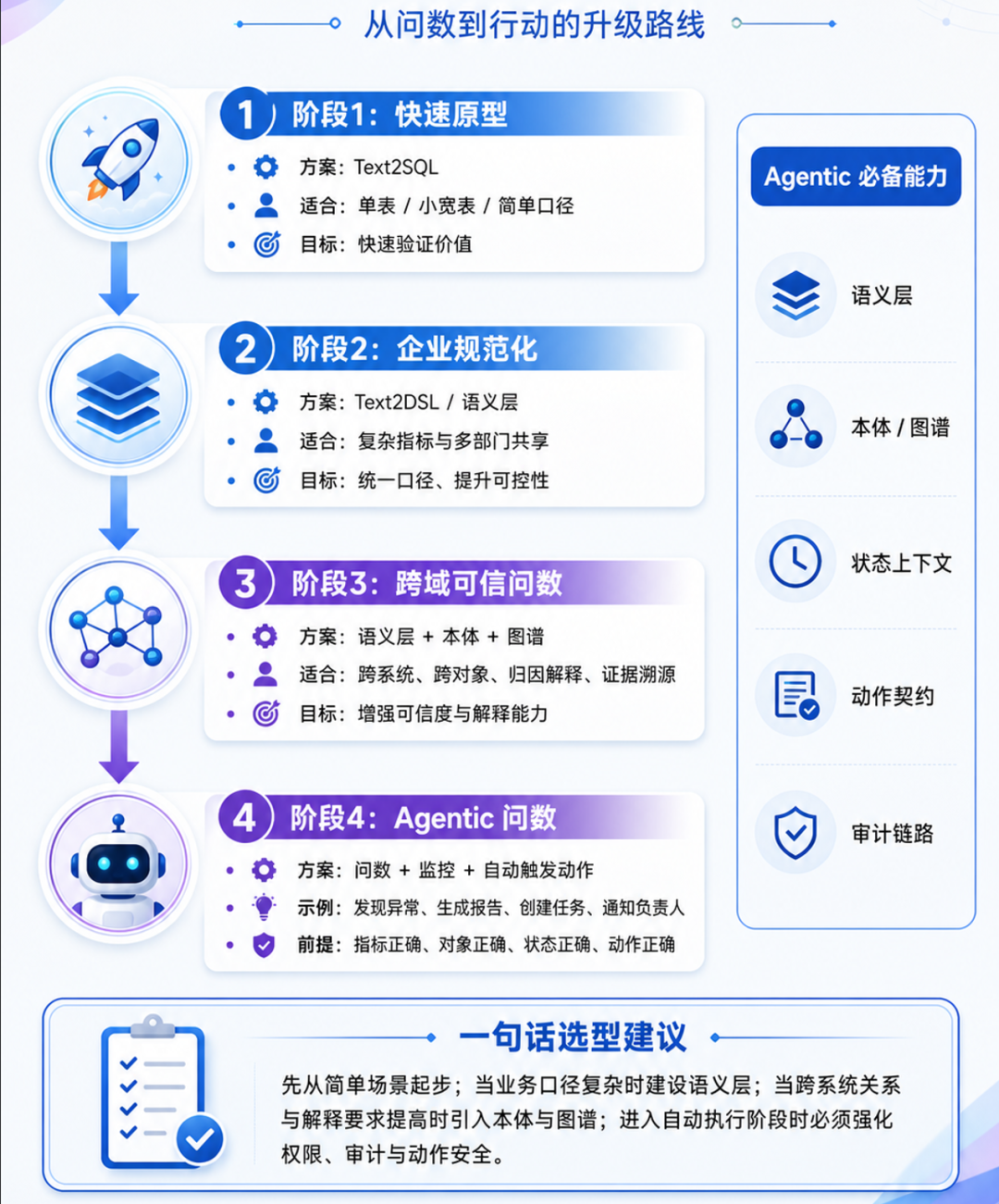
智能问数不是简单让大模型写 SQL。轻量场景可以从 Text2SQL 快速启动,但企业级可信问数通常需要语义层、指标治理、权限治理、查询编译、结果校验和审计链路。跨系统、跨对象、需要归因与证据溯源时,才进一步引入本体和图谱。
未来 Agentic 问数会从“回答数据问题”走向“发现问题并触发行动”,但它能否真正进入企业核心业务,取决于底层可信技术设施是否完备。当前很多 Agentic 产品过于强调 Skill 和 Memory,但 Skill 和 Memory 只是 Agent 的能力表达层;可信数据、可信语义、可信执行、可信审计,才是支撑 Agent 可靠行动的基础。