客户要求,或者想自己部署大模型?
看着几百亿的参数瑟瑟发抖,担心显存随时爆炸?别慌!
这篇文章将带你从理论到实践,彻底搞懂大模型推理的显存占用,让你像专家一样精准规划资源,告别OOM焦虑!
👇👇👇
Part 1
GPU显存去哪了?四大核心占用揭秘
在推理(Inference)一个大模型时,你的 GPU 显存主要被以下四个部分占据:
⚖️ 1. 模型权重 (Model Weights)
这是最直观、最固定的一部分。它的大小就是模型自身的体积。
- 👑 核心地位:
- 这是显存占用的“基本盘”,模型一旦加载,这部分空间就会被持续占用。
- 概念速览:
- 模型权重是神经网络经过训练后学到的数以十亿计的参数(Parameters),正是这些参数构成了模型的“知识”。
- 估算公式:
权重显存 (GB) ≈ 模型参数量 (B) × 单个参数的字节数
单个参数的字节数取决于其数据精度 (Precision):
- FP32 (单精度): 4 字节
- FP16/BF16 (半精度): 2 字节
- FP8 (8位浮点): 1 字节
- INT8 (8位整型): 1 字节
- INT4 (4位整型): 约 0.5 字节 (有少量额外开销)
🧠 2. KV Cache (键值缓存)
这是最关键、也是最具动态变化的部分,是导致长文本或高并发场景下显存爆炸的“罪魁祸首”。
- 💥 性能瓶颈它是评估显存时最大的变量,直接决定了模型能处理多长的文本和多大的并发量。
- 概念速览在自回归生成(一个字一个字地生成)的过程中,模型为了避免重复计算,会将前面所有 token 的“键(Key)”和“值(Value)”缓存起来。后续每生成一个新 token,都要依赖前面所有 token 的 KV 缓存。
- 估算公式:
总 KV 缓存 (GB) = 并发数 × (输入+生成长度) × 每 Token 的 KV 缓存大小
其中,“每 Token 的 KV 缓存大小”由模型架构决定:
每 Token 的 KV 缓存 (Bytes) = 2 (代表k+v)× 层数 × KV 头数量 × 单头维度 × 精度字节数
这里的 KV 头数量 至关重要,它引出了下面这个概念。
🔬 3. 注意力机制变体 (MHA, GQA, MQA)
这三种机制直接影响“KV 头数量”,从而决定了 KV Cache 的大小。
- 💡 优化关键:选择不同注意力机制的模型,其 KV Cache 大小可能有数倍之差。
- 概念速览:
- MHA (多头注意力):原始设计,
查询头数量 = KV 头数量。效果好但 KV Cache 巨大。 - MQA (多查询注意力):极致节省显存,所有查询头共享唯一一套KV 头。
KV 头数量 = 1。 - GQA (分组查询注意力):折中方案,组内共享 KV 头。
1 < KV 头数量 < 查询头数量。在效果和显存之间取得了很好的平衡,是Qwen 、 Llama等主流模型的选择。
📦 4. 激活值、工作空间与框架开销
这是“杂项”开销,虽然不如前两者量级大,但不可忽略。
- ⚠️ 安全余量需要为其预留一定的冗余空间,否则也可能导致OOM。
- 概念速览:
- 激活值 (Activations):计算过程中的临时中间变量。
- 工作空间 (Workspace):底层计算库(如 cuDNN)预分配的临时显存。
- 框架开销:推理框架(如 vLLM, TensorRT-LLM)自身运行也需要少量显存。
经验法则:通常将这部分估算为“权重 + KV Cache”总和的 5% 到 20% 作为安全余量。
表:qwen3-coder-plus阶梯费用表
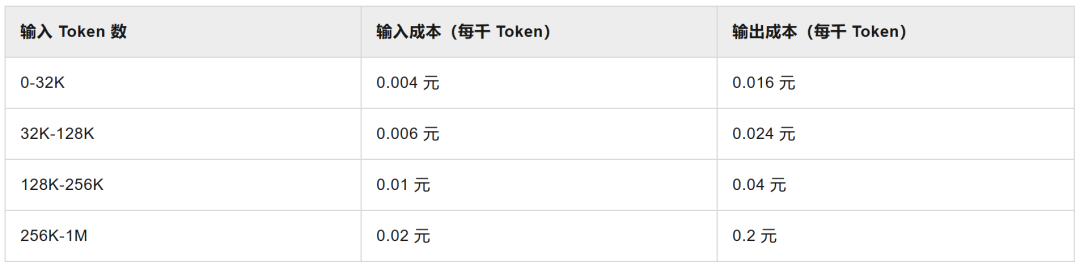
注:不同长度上下文的KV Cache成本不同,所以有些模型按照输入Token数进行阶梯收费。
Part 2
实战演练:手把手带你评估 Qwen3-8B
理论讲完,我们来上手实战!假设我们要部署 ModelScope 上的 Qwen/Qwen3-8B。
🕵️♂️ 第 1 步:当侦探,从模型文件中寻找线索
在模型仓库页面找到并打开配置文件 config.json,寻找以下关键字段:
"num_hidden_layers": 36 (模型层数 L)"num_attention_heads": 32 (查询头 Q 的数量)"num_key_value_heads": 8 (键值头 KV 的数量)"head_dim": 128 (单头维度)"torch_dtype": "bfloat16" (默认精度,2 字节)
同时,从模型介绍(README)中我们得知:
- 模型参数量: 8.2B (82亿)
- 上下文长度: 原生支持 32,768 tokens
✨ 关键判断
因为 num_key_value_heads (8) 介于 1 和 num_attention_heads (32) 之间,我们明确判断 Qwen3-8B 使用的是 GQA 架构。这意味着计算 KV Cache 时,应使用 KV 头数量 = 8,而不是 32!
🧮 第 2 步:做算术,计算各部分显存
计算模型权重显存 (静态)
- 权重显存 = 8.2 Billion × 2 Bytes/Param ≈ 16.4 GB
计算每 Token 的 KV Cache 大小 (动态核心)
- 代入公式:
2 × L × H_kv × d_head × 精度字节数 L=36,H_kv=8,d_head=128- BF16/FP16 (2字节) KV Cache: 2 × 36 × 8 × 128 × 2 Bytes ≈ 144 KB / token
- INT8/FP8 (1字节) KV Cache: 大小减半,约 72 KB / token
📊 第 3 步:情景分析,制作显存预算表
现在我们可以估算不同场景下的总显存了。
总显存 ≈ 权重显存 + (并发数 × 总 token 数 × 每 token KV 缓存) + 10%安全余量
Qwen3-8B (BF16 权重, 16.4GB) 显存占用估算表
| 场景描述 | 并发数 | 总 Token | KV Cache 精度 | KV Cache 占用 (GB) | 总预估显存 (GB) (含10%余量) |
|---|---|---|---|---|---|
| 单次短对话 | 1 | 4,096 | FP16 | 0.56 | (16.4 + 0.56) × 1.1 ≈ 18.7 |
| 单次长文本 | 1 | 32,768 | FP16 | 4.50 | (16.4 + 4.50) × 1.1 ≈ 23.0 |
| 单次长文本 | 1 | 32,768 | FP8 | 2.25 | (16.4 + 2.25) × 1.1 ≈ 20.5 |
| 小批量短对话 | 8 | 4,096 | FP16 | 4.50 | (16.4 + 4.50) × 1.1 ≈ 23.0 |
| 小批量短对话 | 8 | 4,096 | FP8 | 2.25 | (16.4 + 2.25) × 1.1 ≈ 20.5 |
| 极限长上下文 | 1 | 131,072 | FP8 | 9.00 | (16.4 + 9.00) × 1.1 ≈ 28.0 |
💡 解读与结论:
对于一张 24GB 显存的显卡 (如 RTX 3090/4090):
- 直接用 FP16 跑
Qwen3-8B处理 32K 上下文是可行的,但已接近上限,几乎没有并发能力。 - 如果启用 FP8 KV Cache 量化,显存压力显著降低!不仅能轻松跑32K上下文,还能支持8个并发的短对话,性价比极高。
- 更进一步如果想在 24GB 显卡上实现更高并发或处理131K超长上下文,就需要对 16.4GB 的权重本身进行量化(如4-bit),为 KV Cache 腾出巨大空间。
Part 3
🚀 性能魔法:揭秘推理框架的“黑科技”
现代推理框架(如 vLLM, TensorRT-LLM)引入了许多优化技术,理解它们能帮你更好地进行容量规划。
🧠 KV Cache:推理性能的"记忆宫殿"
- 痛点在自回归生成过程中,模型需要"看到"之前所有token的信息才能生成下一个token。如果每次都重新计算,计算量会呈平方级增长,推理速度会慢到无法接受。
- 神技KV Cache 巧妙地将每个token的Key和Value向量缓存起来,后续生成时直接复用这些缓存,避免了重复计算。这就像给模型建了一座"记忆宫殿",让推理速度提升数十倍。
- 效果速度飞跃
- 从O(n²)的计算复杂度降低到O(n),推理速度提升10-100倍。
- 显存占用每个token的KV Cache大小固定,总占用与序列长度成正比。
- 并发瓶颈多请求并发时,KV Cache成为显存占用的主要瓶颈,需要精细管理。
📄 PagedAttention:从根本上解决显存浪费
- 痛点传统 KV Cache 需要为每个请求预留一块连续的、能容纳其最大可能长度的显存。这导致了巨大的浪费和内存碎片,浪费率可高达 60-80%。
- 神技PagedAttention 借鉴操作系统“分页”的思想,将 KV Cache 拆分成许多固定大小的小块(Blocks)。一个请求的 KV Cache 由一系列非连续的块组成。
- 效果消除碎片
- 空间利用率极高,浪费率降至 4% 以下。
- 吞吐翻倍同样显存下能容纳更多请求,官方称可提升 2-4 倍吞吐量。
- 预算精确让我们的估算公式更接近真实物理占用。
gpu_memory_utilization:显存预分配的艺术
- 概念vLLM 中的一个重要参数,默认为
0.9。它告诉 vLLM:“你可以动用 GPU 总显存的 90% 来预先创建一个大的内存池,专门存放 KV Cache 的 Blocks”。 - 权衡之道
- 设得高 (如 0.95)
- KV 池更大,吞吐潜力高。但留给其他开销的余量少,有 OOM 风险。
- 设得低 (如 0.8)更保守,不易 OOM。但池子较小,请求多时可能排队,增加延迟。
- 建议从默认的
0.9开始,根据实际负载和监控进行微调。
Chunked Prefill:优化长输入处理
- 痛点一个很长的输入请求会长时间霸占 GPU,让后面的短请求排队等待,整体响应变慢。
- 神技将长输入的计算过程切分成小块(Chunks),并允许这些小块与其他请求的生成步骤混合排队执行。
- 效果它不改变总 KV Cache 大小,但通过更精细的调度,提高了 GPU 利用率,显著改善了混合负载下的系统吞吐和公平性。
Part 4
✅ 总结:你的专属四步评估清单
当你面对一个新模型,想要评估其部署所需显存时,可以遵循以下流程:
1. 🔎 信息搜集 打开模型的 config.json 和 README,找到 参数量、层数、Q/KV 头数量、单头维度 和 默认精度。
2. ⚖️ 静态计算 根据参数量和目标权重精度,计算出模型权重的静态显存占用。
3. 🧠 动态计算 根据层数、KV 头数和单头维度,计算出每 token 的 KV Cache 大小。然后结合你的业务场景(预估的并发数、最大总长度),计算出峰值 KV Cache 的动态占用。
4. 📊 综合评估 将权重和峰值 KV Cache 相加,并增加 10-20% 的安全余量。将此结果与你的目标 GPU 显存对比,判断是否可行,以及是否需要启用权重量化或 KV Cache 量化等优化手段。