上一篇《智能问数技术路线与选型》中,我们梳理了智能问数的几种主流技术路线,并提到:语义层是企业级智能问数的核心基础设施。
本文将介绍一个典型的开源语义层框架:Cube Core(https://github.com/cube-js/cube)。需要说明的是,Cube 这个名字在不同语境下有两层含义:狭义上,它指可自托管的开源语义层 Cube Core;广义上,它也可以指 Cube 公司围绕 Cube Core 构建的完整产品体系,包括 Cube Cloud、Cube Platform 以及 Agentic Analytics 等商业化能力。本文主要讨论 Cube Core,但为了理解其演进方向,也会适当涉及 Cube 商业产品体系中的能力。
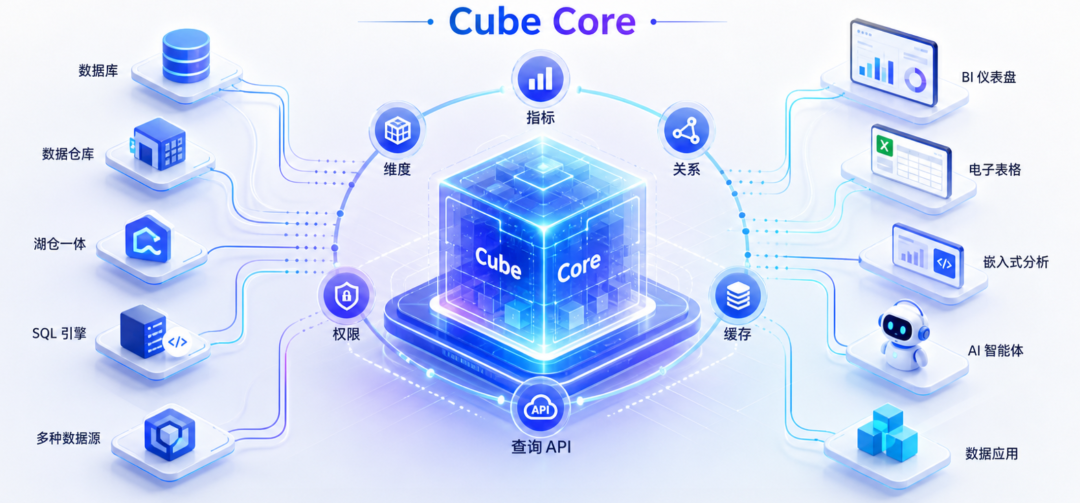
Cube Core 是一个面向 BI、嵌入式分析和 AI Agent 的开源语义层。它让 AI、BI 工具和应用通过语义层发起查询,而不是直接访问底层数据源。这对智能问数非常关键;在企业级问数场景中,问题通常不是“LLM 会不会写 SQL”,而是:
- GMV 到底怎么算;
- 新客怎么定义;
- 收入是否含退款;
- 本月是自然月还是财务月;
- 这个用户能不能看这个部门的数据;
- 多张表之间应该走哪条 join 路径;
- 结果是否命中了缓存,是否可追溯。
Cube 的定位,就是把这些指标口径、维度关系、权限规则和查询加速能力前置到语义层中,让上层的 BI 工具、应用和 AI Agent 面对稳定、可治理的业务语义对象进行问数。
数据库 / 数仓 / 湖仓 / 查询引擎
↓
Cube 语义层
- 指标
- 维度
- 关系
- 权限
- 缓存
- 查询接口
↓
BI 工具 / Excel / 嵌入式分析 / AI Agent / 数据应用接下来,我们先回顾 Cube 的发展历程,帮助读者理解它为什么适合语义层和智能问数场景;再梳理它的核心功能和架构。
Cube 体系的发展历程
Cube 最早起源于“嵌入式分析”和“数据应用”场景。
Cube的历史可以追溯到2016年,当时Cube的创始人Artyom Keydunov 和 Pavel Tiunov 创办了一个叫做 Statsbot 的数据公司,经常处理数据建模、指标口径和数据资产等治理问题。
随着业务的发展,Statsbot 团队发现,当时数据工程师已经有不少内部数据基础设施工具,但软件工程师在构建生产级、客户可见的嵌入式分析功能时,缺少既能高度定制前端、又能支撑大数据规模、同时不需要复杂数据流水线的工具。
在当时,很多 SaaS、运营系统、客户后台里,开发者都需要给用户做报表、指标面板、趋势图、漏斗、留存、排行榜等功能。这个场景和传统 BI 不太一样:
- 前端要高度定制;
- 查询要能承受很多外部用户并发;
- 指标口径要稳定;
- 权限和多租户要严格;
- 查询不能每次都直接打到底层数仓;
- 不能要求每个应用团队都维护复杂数据流水线。
阶段1:2019 年,Cube.js 开源
2019年3月,基于对自身和行业的需求理解,Pavel Tiunov 和 Artyom Keydunov 将核心功能打包成Cube.js并进行了开源。值得一提的是,Cube.js 在开源前已经在多家公司生产环境运行一年以上,并处理过 PB 级数据集。Cube开源后数月内就有数千名开发者开始基于 Cube.js 构建应用。
早期 Cube.js 的一个重要设计是 visualization-agnostic,也就是不绑定可视化层。官方当时明确说,不去重新发明一个可视化库,而是让 Cube.js 只负责后端数据查询和结果处理,前端可以接 Chart.js、D3、React、Vue 等任意组件。这使得 Cube.js 很适合下面这些场景:
- SaaS 产品里嵌入客户报表;
- 运营后台里的自定义仪表盘;
- 面向外部客户的 analytics portal;
- 内部数据应用;
- 需要 API-first 的分析后端。
阶段2:2020 年,从开源项目到公司化运营
Cube.js 在 2019 年 3 月开源后,社区和生产使用增长很快。2020 年,Cube Dev 宣布融资 620 万美元,当时 Cube.js 已经部署到全球企业的 70,000 多台服务器上。
这一阶段 Cube 的定位还是“现代分析应用基础设施”。它解决的问题不是自然语言问数,而是:
- 指标如何统一定义;
- 查询如何通过 API 暴露;
- 缓存和预聚合如何管理;
- 多租户和权限如何控制;
- 如何让开发者更快构建数据应用。
同时,Cube Dev 也开始规划 Cube Cloud。官方当时说,核心能力会继续开源,服务端代码采用 Apache 2.0,前端采用 MIT,同时会建设商业版 Cube Cloud 来帮助开发者部署、扩展和运维 Cube.js。
阶段3:2021 年,Cube Store 出现,查询性能成为关键能力
随着 Cube 被用于更多生产环境,团队发现,单纯把查询转换成 SQL 还不够。当时分析查询的瓶颈经常是:
- 用户并发高;
- 数据量大;
- 查询维度多;
- TopN、时间趋势、分组聚合很多;
- 每次都查数仓成本高、延迟高。
因此 Cube 推出了 Cube Store。Cube Store 是 Cube 的专用预聚合存储层,用来支撑高并发和低延迟查询。官方在 2021 年发布 Cube Store GA 时说明,它是 Cube.js 的 custom pre-aggregation storage layer,目标是让 Cube.js 在任意 SQL-compliant 数据库、数仓或查询引擎之上,为高并发应用提供亚秒级延迟。
Cube Store 的结构大致是:
Cube API
→ 命中预聚合
→ Cube Store Router
→ Cube Store Workers
→ Parquet / Blob StorageCube Store 使用分布式查询引擎架构:router 负责连接、元数据、查询计划和调度,worker 负责摄取和并行执行查询,预聚合数据以列式格式存储在本地或云对象存储中。官方还说明,Cube Store 用 Rust 编写,并使用 Parquet、Apache Arrow 和 DataFusion 等开源组件。
这一阶段,Cube 开始从“分析 API 框架”变成“语义层 + 查询加速层”。对智能问数而言,这意味着语义层不仅负责“定义口径”,还可以“让查询结果可在交互场景中快速返回”。
阶段4:2021 年,Cube Cloud、SQL API、GraphQL API 推动 Headless BI
同样在 2021 年,Cube 还发生了几个重要变化。
第一,Cube Cloud GA。Cube Cloud 是托管版 Cube,目标是让开发者不用自己管理 Cube 的部署、扩缩容、监控、查询追踪、预聚合刷新和安全配置。官方发布时说,Cube Cloud 是 fully managed service for running Cube applications,并提供 API 实例自动扩缩、缓存和预聚合 warm-up、GitHub 集成、协作 schema 编辑、监控、查询追踪、预聚合管理和安全能力。
第二,Cube 发布 SQL API。这个变化很关键,因为它让 Cube 不再只是给应用前端提供 JSON/REST API,而是可以像一个数据库一样被 BI 工具连接。官方在 SQL API 发布文章中明确说,Cube 可以作为 metrics store,为任何数据消费者提供一致指标,并成为 headless BI layer。
第三,Cube 发布 GraphQL API。GraphQL API 让 Cube 可以作为应用 GraphQL 层的一部分,为前端和应用提供指标数据。官方也把 SQL API 和 GraphQL API 视为走向 universal, headless analytics layer 的重要步骤。
这一阶段 Cube 的路线可以概括为:
统一指标定义
→ 多协议查询接口
→ BI / 应用 / 前端都能消费
→ Headless BI阶段5:2022 年,从 Cube.js 改名为 Cube
2022 年,Cube.js 正式改名为 Cube。官方解释说,这个改名虽然表面上只是名称变化,但反映了 Cube 从“开源 JavaScript 分析框架”演进为 headless BI platform。
这个改名很有代表性。因为早期叫 Cube.js,会让人以为它是类似 Chart.js、D3.js 的前端可视化库。但实际上 Cube 已经变成一个更底层的数据基础设施:
- 不只是 JavaScript;
- 包含 Rust 写的 Cube Store;
- 不只是应用前端工具;
- 支持 SQL API、GraphQL API;
- 面向 BI、嵌入式分析、指标层和语义层;
- 开始成为独立于具体 BI 工具的 headless BI / semantic layer。
因此,Cube.js 改名为 Cube,本质上是产品定位从“JS 分析框架”升级为“通用语义层”。
阶段6:2024 年以后,Cube 明确进入 AI 语义层方向
大模型出现后,企业开始尝试让 AI 直接查数据。但直接 Text2SQL 很快会遇到问题:
- 不知道指标口径;
- 不知道 join 路径;
- 不知道权限;
- 不知道业务别名;
- 不知道时间口径;
- 生成 SQL 很难稳定校验;
- 同一个问题在不同工具里答案可能不一致。
Cube 正好切入这个问题。
2024 年 Cube 宣布完成 2500 万美元融资,其中 Databricks 参与了战略投资。Cube 在文章中回顾说,2019 年他们启动 Cube,是为了创建一个统一管理 data models、security 和 caching 的地方;到 2024 年,Cube Cloud 的定位已经是位于数据源和数据应用之间的 universal semantic layer,可以把同一套语义提供给 BI、Excel、嵌入式分析和 AI agents。
也就是说,Cube 在 AI 时代的价值不只是“帮大模型写 SQL”,而是为 AI 提供一个确定性、可治理、可复用的语义层。
阶段7:2025 年,Cube 进一步走向 Agentic Analytics
2025 年,Cube 发布 D3,也就是 data in cube,把它定义为基于 Cube 语义层构建的 agentic analytics platform。D3 包括 Analytics Chat、Workbooks、Data Apps、Semantic Modeling 等能力,目标是让 AI Agent 和人协同完成建模、探索和报告。
后来 Cube 又宣布 Cube Agentic Analytics GA,并去掉 D3 名称,把语义层和 agentic analytics 产品统一到 Cube 这个单一品牌下。官方描述的愿景是:agents 和 humans 一起工作,从 modeling 到 exploration 再到 presentation,同时人类保留细粒度控制。
至此,Cube 的发展路线大致变成:
Cube.js 开源嵌入式分析框架
→ Cube Store 查询加速
→ Cube Cloud 托管平台
→ SQL / GraphQL / REST 多协议 Headless BI
→ Universal Semantic Layer
→ AI / BI / Embedded Analytics 统一语义层
→ Agentic AnalyticsCube 的核心功能
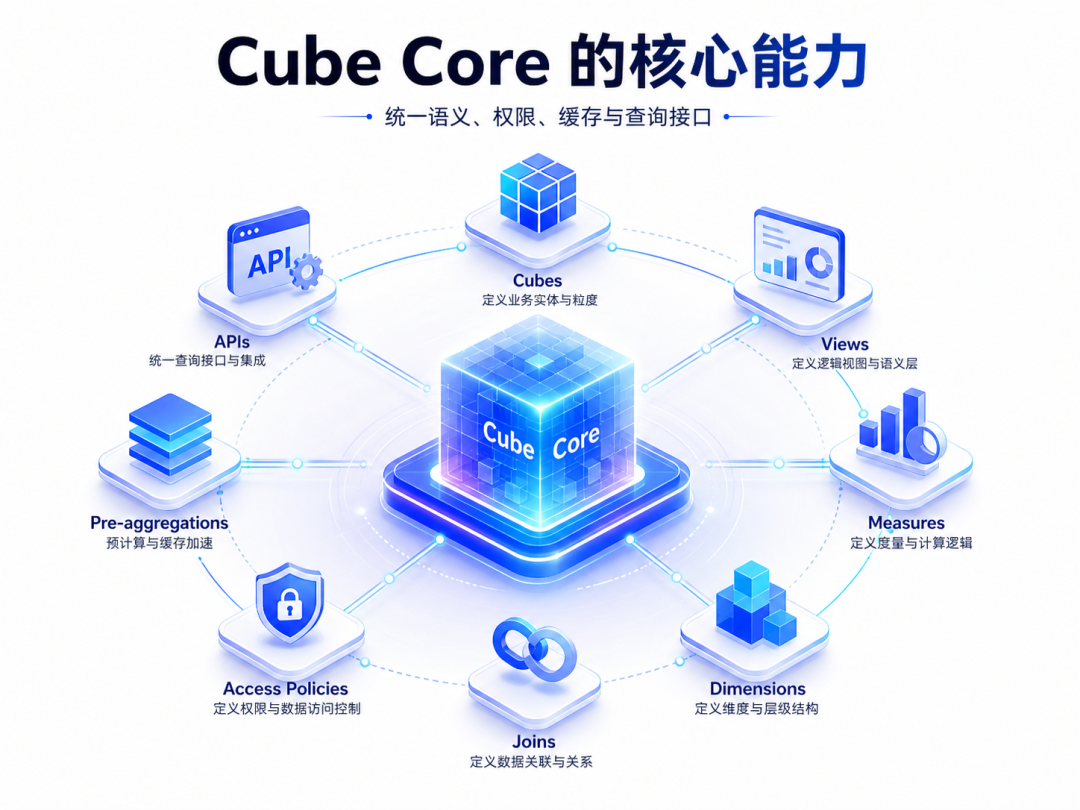
前面我们介绍了Cube的发展历史,接下来我们讲一下Cube的核心功能。Cube 的功能可以分成几层来看。
数据建模:定义业务对象、指标、维度和关系
Cube 的数据模型以 cubes 为核心。Cube 官方说明,Cube 的数据模型是包含 measures 和 dimensions 的实体关系图;在 Cube 中,实体被称为 cubes,本质上是带有语义元数据的数据表,描述 measures、dimensions 以及与其他 cubes 的关系。
典型建模对象包括:
- Cube:业务实体,比如 orders、users、products、payments;
- View:面向消费端的数据产品视图。
- Measure:指标,比如订单数、销售额、GMV、转化率;
- Dimension:维度,比如渠道、地区、商品、用户类型;
- Segment:常用条件,比如已支付订单、活跃用户、新客;
- Join:实体关系,比如订单关联用户、订单关联商品;
可以简单理解为:
底层表:orders
业务对象:订单
指标:订单数、支付金额、退款金额
维度:订单状态、渠道、城市、创建时间
关系:订单 → 用户,订单 → 商品,订单 → 门店Cube 新版文档把 Cubes 和 Views 区分得更明确:Cubes 表示 customers、line items、orders 等业务实体,定义 measures、dimensions 和实体之间的关系;Views 位于 cubes 的数据图之上,作为 AI agents、BI users 和 applications 交互的最终数据产品。
这意味着 Cube 不只是“字段别名表”,而是一个业务语义图。
查询接口:REST、GraphQL、SQL、DAX、MCP
Cube 的一个重要特点是 API-first / headless。
它不是只服务某一个 BI 前端,而是提供多种标准协议,让不同消费端都能接进来。
官方文档列出的 Core Data APIs 包括 SQL、DAX、REST JSON 和 GraphQL;同时文档也提到,AI assistants (商业化)可以使用 MCP server,Power BI 可以使用 DAX API,嵌入式分析和实时分析可以使用 REST 或 GraphQL API。
这也是 Cube 能从嵌入式分析扩展到 BI 和 AI 的基础。
查询编译:从语义查询生成底层 SQL
Cube 的查询不是直接暴露底层 SQL 表,而是暴露语义对象。
在 SQL API 中,Cube 会把每个 cube 或 view 映射成表,把 measures、dimensions、segments 映射成列;查询方可以像查普通表一样查 Cube,但底层计算仍然由 Cube 根据语义模型生成。官方文档还说明,measure 可以通过特殊的 MEASURE 聚合函数引用。
这对智能问数很重要。
因为如此一来, LLM 面对的是清晰的语义层对象:
orders.count
orders.total_revenue
orders.created_at
customers.region
products.category而不是:
ods_order_detail_v3
dw_user_dim_202404
fact_payment_refund_daily语义层把底层复杂 SQL、表结构和计算逻辑藏起来,让上层只面对稳定的业务对象。
缓存与预聚合:让问数不只是“能答”,还要“答得快”
企业问数系统如果每次都直接打数仓,会遇到两个问题:
- 延迟高,用户体验差;
- 成本高,尤其是在云数仓按查询收费时。
Cube 的核心能力之一就是缓存和预聚合。
Cube 文档说明,Cube 通过 pre-aggregations 实现 aggregate awareness。数据团队在模型中定义 rollup tables,Cube 在后台构建和刷新这些预聚合,并把结果存储到 Cube Store;当查询到来时,如果有可用且新鲜的预聚合,Cube 会用预聚合服务查询,从而降低延迟和数仓成本。
典型结构是:
原始数据表
→ Cube 后台构建预聚合
→ Cube Store 存储 rollup
→ 用户查询时优先命中预聚合
→ 必要时再查底层数仓这使得 Cube 不只是语义层,也是查询加速层。
权限治理:行级、成员级、上下文权限
智能问数进入企业场景后,权限是绕不开的问题。
用户问:
这个月各区域销售额是多少?
系统必须知道:
- 用户属于哪个部门;
- 能不能看所有区域;
- 能不能看金额字段;
- 是否只能看自己负责的客户;
- 返回结果是否要脱敏;
- AI Agent 是否也遵守同样权限。
Cube 的 Access Policies 可以控制 cubes 和 views 上的 row-level security 和 member-level security,也就是限制用户能看到哪些行、哪些指标或维度。
新版 Cube 文档进一步强调,访问控制集中在语义层后,AI agents、BI tools 和 custom applications 都必须通过同一个 governed checkpoint,从而防止 Agent 无意暴露敏感数据或违反安全策略。
这也是语义层相比直接 Text2SQL 的优势之一:不是依赖 AI 自行理解和遵守权限规则,而是让所有查询都经过确定性的权限控制层。
当然,对于已经建设完善 BI 或数据治理体系的企业,权限控制可能已在现有架构中部分实现,Cube 的价值更多在于统一承接这些规则。
Cube 的架构
Cube 的逻辑架构可以概括为:
数据源
- Snowflake
- BigQuery
- Databricks
- Postgres
- MySQL
- ClickHouse
- Trino / Presto
- 其他 SQL 数据源
↓
Cube Semantic Layer
- Cubes
- Views
- Measures
- Dimensions
- Joins
- Segments
- Access Policies
- Pre-aggregations
↓
Cube APIs
- REST
- GraphQL
- SQL
- DAX
- MCP
- SDK
↓
消费端
- BI 工具
- Excel / Sheets
- 嵌入式分析
- AI Agent
- Analytics Chat
- 数据应用根据官方架构文档,一个典型的 Cube Core 生产部署包括一个或多个 API instances、一个 Refresh Worker 和一个 Cube Store cluster。API instances 处理外部 API 请求,并查询 Cube Store 或连接的数据源;Refresh Worker 在后台构建和刷新预聚合;Cube Store 接收 Refresh Worker 构建的预聚合,并响应 API instances 的查询。
其中:
- API Instances:负责接收查询、鉴权、编译查询、返回结果;
- Refresh Worker:负责刷新预聚合、维护 refresh keys、失效化缓存;
- Cube Store:负责存储和查询预聚合数据;
- Router / Workers:Cube Store 内部的分布式查询组件;
- Blob Storage:保存列式预聚合数据。
简单说,Cube 的生产架构不是一个轻量 SQL wrapper,而是一个带语义模型、权限控制、缓存编排和分布式预聚合存储的分析服务层。
Cube 适合什么场景
Cube 比较适合下面这些场景:
| 场景 | 是否适合 Cube | 原因 |
|---|---|---|
| 单表、小宽表、临时问数 | 不一定需要 | Text2SQL 可能更快 |
| 一次性分析探索 | 不一定适合 | 建模成本可能高于收益 |
| SaaS 产品嵌入客户报表 | 很适合 | 需要 API、缓存、多租户、权限 |
| 企业统一指标层 | 很适合 | 需要统一 metrics 和 dimensions |
| 多 BI 工具共用指标 | 很适合 | SQL API / Semantic Layer Sync 可复用语义 |
| Agent 智能问数 | 很适合 | AI 查询语义层,而不是直接查库 |
| 跨部门复杂指标治理 | 适合,但需要建模投入 | 需要完整语义模型和权限治理 |
| 没有数据治理基础的企业 | 可以用,但不能神奇解决脏数据 | 上游数据质量是关键 |
Cube 不能解决什么
Cube 不能自动修复上游脏数据,不能替代数仓建模,不能自动统一公司内部对指标的组织共识,也不能单独完成自然语言问数体验。它解决的是“统一语义、统一查询、统一权限、统一加速”的基础设施问题。引入 Cube 的前提是企业愿意投入语义建模。
结语
Cube 的本质不是一个“让大模型写 SQL 的工具”,而是一个把企业数据语义产品化的基础设施。
它的发展路径很清晰:
嵌入式分析框架
→ 分析 API
→ 预聚合和查询加速
→ Headless BI
→ Universal Semantic Layer
→ AI / Agentic Analytics对智能问数来说,Cube 代表的是一条更企业级、更可治理的技术路线:
不是让 LLM 直接面对数据库
而是让 LLM 面对语义层
不是每次临时生成口径
而是提前治理指标、维度、关系和权限
不是只追求能回答
而是追求可控、可信、可复用、可追溯、可扩展可以这么理解:轻量问数可以从 Text2SQL 起步;但如果目标是企业级可信问数,尤其在 Agent、Agentic AI等场景,Cube 这类语义层产品是非常典型的技术选型。