在AI系统开发中,我们常看到一个模型发布时的参数是几百K,但是云平台上API接口的说明显示只支持几十K的输出,不同的平台支持的输出长度还不一样,今天我们分析下这是为什么。
一、为什么“上下文窗口”很大,但“输出长度”受限?
这个现象的核心原因在于,处理输入和生成输出这两种操作在计算成本、资源消耗和质量控制上存在巨大的不对称性。
1. 成本的非对称性:一次性的“预填充” vs. 逐字的“解码”
模型的推理过程分为两个阶段,它们的成本截然不同:
预填充 (Prefilling):当我们输入一个长篇提示词时,模型会并行计算所有输入词元(Token)之间的自注意力关系。这虽然计算量巨大(复杂度与输入长度的平方成正相关),但它是一次性的、高度并行的“读入”成本。 解码 (Decoding):模型的生成过程是自回归 (Auto-regressive) 的,即一个字一个字地生成。每生成一个新的字,模型都必须回头关注全部的上下文(包括原始输入和所有已经生成的内容)。因此,输出越长,后续每个字的生成速度就越慢,总耗时和计算成本会持续累加。
一个比喻:预填充就像是用一秒钟拍下一整张宏大的风景照(并行处理);而解码则像是在这张照片上一个像素一个像素地作画,每画一个新像素,都要回头审视整张照片以确保和谐(串行处理)。输出越长,这幅画就越大,作画的时间就越不成比例地增加。
2. KV缓存资源
为了加速解码过程,模型会使用一种名为 KV缓存 (KV Cache) 的技术,将上下文中每个词元的关键计算结果(Key和Value)存储在显存中。但这带来了巨大的显存开销。
KV缓存有多大? 以一个采用分组查询注意力(GQA)的中等模型为例,每个词元(Token)的KV缓存大小可能在100KB以上。 这意味着什么? 如果一个模型的上下文窗口是400k(约40万个词元),仅KV缓存一项就可能占用 400,000 * 128KB ≈ 51.2GB的显存。这已经超过了许多顶级GPU(如NVIDIA A100 40GB/80GB)的容量。如果再允许无限制地长输出,KV缓存会持续增长,很快就会导致显存溢出,拖垮整个推理服务。因此,限制输出长度是保障服务稳定性的必要之举。
3. 系统吞吐量与公平性
在多租户的云服务环境中,平台需要同时处理成千上万个请求。
动态批处理 (Dynamic Batching):为了提高GPU利用率,平台会将多个用户的请求打包成一个批次来处理。 长输出的破坏性:一个请求如果要求生成非常长的输出,会长时间“霸占”批处理中的一个位置,导致其他用户的短请求被阻塞,严重影响整体的服务响应速度(SLO,服务等级目标)和公平性。因此,设定一个合理的输出上限,是维持系统高吞吐量和用户体验的必要策略。
4. 输出质量与可控性
质量下降:即使模型支持长上下文,在生成超长文本时,也容易出现逻辑漂移、前后矛盾、内容重复、甚至“忘记”开头指令等问题。这部分源于训练数据中“超长、高质量、一镜到底”的样本相对稀少。 安全与合规:较短的输出更容易进行内容安全审核。无限长的输出会增加被滥用于生成有害、违规内容的风险,给平台带来合规挑战。
可以把支持128k上下文的大模型想象成一位记忆力超群、学识渊博的学者:
长输入能力: 你可以让他花一天时间读完一套《大英百科全书》(相当于128k的长输入)。凭借超凡的记忆力和理解力,他能完全吸收其中的内容。 短输出能力: 读完之后,你问他“请总结一下第二次工业革命的关键技术及其影响”,他可以迅速给出一个几千字的、条理清晰、引用准确的精彩回答(高质量的输出)。 长输出的挑战: 但如果你对他说“请你现在马上写一本全新的、500页的关于未来科技的专著”,他很可能会拒绝,或者即使开始写,写到后面也很容易出现前后矛盾、思路枯竭的问题。一个负责任的学者会选择先列提纲、分章节写作、反复修改,而不是一气呵成。
二、为什么同一模型在不同平台上的输出限制不同?
同一个模型在不同平台上支持的最大输出长度也可能不同,这是由各平台在推理服务层的工程实现、硬件配置和商业策略上的差异决定的,而非模型本身的能力不同。
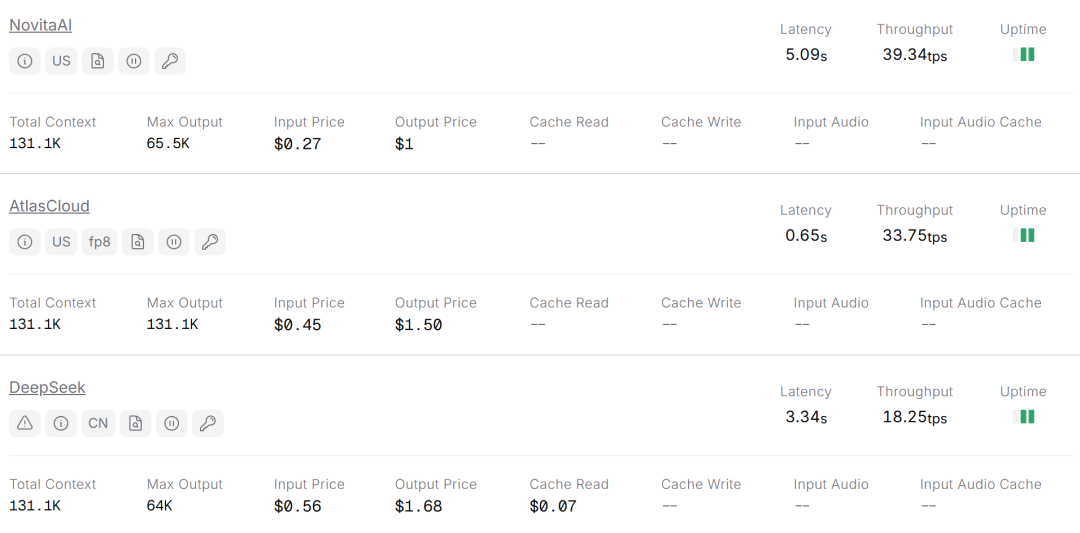
硬件与推理引擎的差异:不同平台使用的GPU(如H100 80GB vs A100 40GB)、服务器架构以及推理优化引擎(如vLLM、TensorRT-LLM等)各不相同。更先进的硬件和更高效的推理引擎(例如通过PagedAttention等技术优化KV缓存管理),自然能支持更长的输出。 商业策略与产品定位:平台会根据不同的付费套餐(免费、专业、企业版)来设定不同的输出配额。长输出作为一种高成本资源,通常被用作高级功能的区分点。 服务等级目标(SLO)与风险阈值:不同平台对服务稳定性、最大延迟和内容风险的容忍度不同。一家追求极致稳定性和快速响应的平台,可能会设置一个更保守的输出上限。 API设计与语义:有些平台将最大输出长度设为硬性上限,不可逾越;而另一些平台可能将其作为默认值,允许企业客户或通过特定申请来调高这一限制。
三、开发实践
理解了上述原理后,我们在实际应用中可以采取更智能的策略:
按需申请,精准控制:在调用API时,根据当前任务的实际需要,显式地设置 max_output_tokens参数,仅申请必要的长度,避免浪费资源和触及平台上限。化整为零,分段生成:对于长文本生成任务(如写报告、小说),应采用“规划-提纲-分章节生成-整合”的模式。通过多次调用、让模型“续写”或“完成下一部分”,比一次性要求生成全文的质量和稳定性要高得多。 结合检索,增强框架:利用检索增强生成(RAG)技术,先为长文生成提供结构化的知识和提纲,然后让大模型负责将这些要点“润色”和“扩写”成高质量的短段落,最后再进行拼接。 设计容错与重试机制:在代码中捕获因达到输出上限而中断的错误,并自动发起“续写”请求,实现无缝的长内容生成体验。 审慎选择平台:如果核心业务确实需要一次性生成较长的内容,那么应在选型时将各平台的 max_output_tokens限制作为一个关键考量因素。
总结
“大上下文”是模型强大的阅读理解能力范围,而“小输出”主要是平台为了平衡计算成本、显存压力、系统吞吐量和输出质量而设定的工程与商业安全阀。同一模型在不同平台的输出上限各异,本质上是各家推理服务的硬件、软件和运营策略的综合体现,而非模型本身能力的差异。