最近看社交软件中,网友们关于智能问数的讨论时,发现不少评论来自亲身体会,我想如果搜集起来,做一次归纳分析,或者有点意思。
于是搜集了472评论,其中主评论267条,整理成此篇文章。
搜集的关键词覆盖:智能问数、chatBI、text2sql、数据分析 agent、问数落地。排除广告贴。
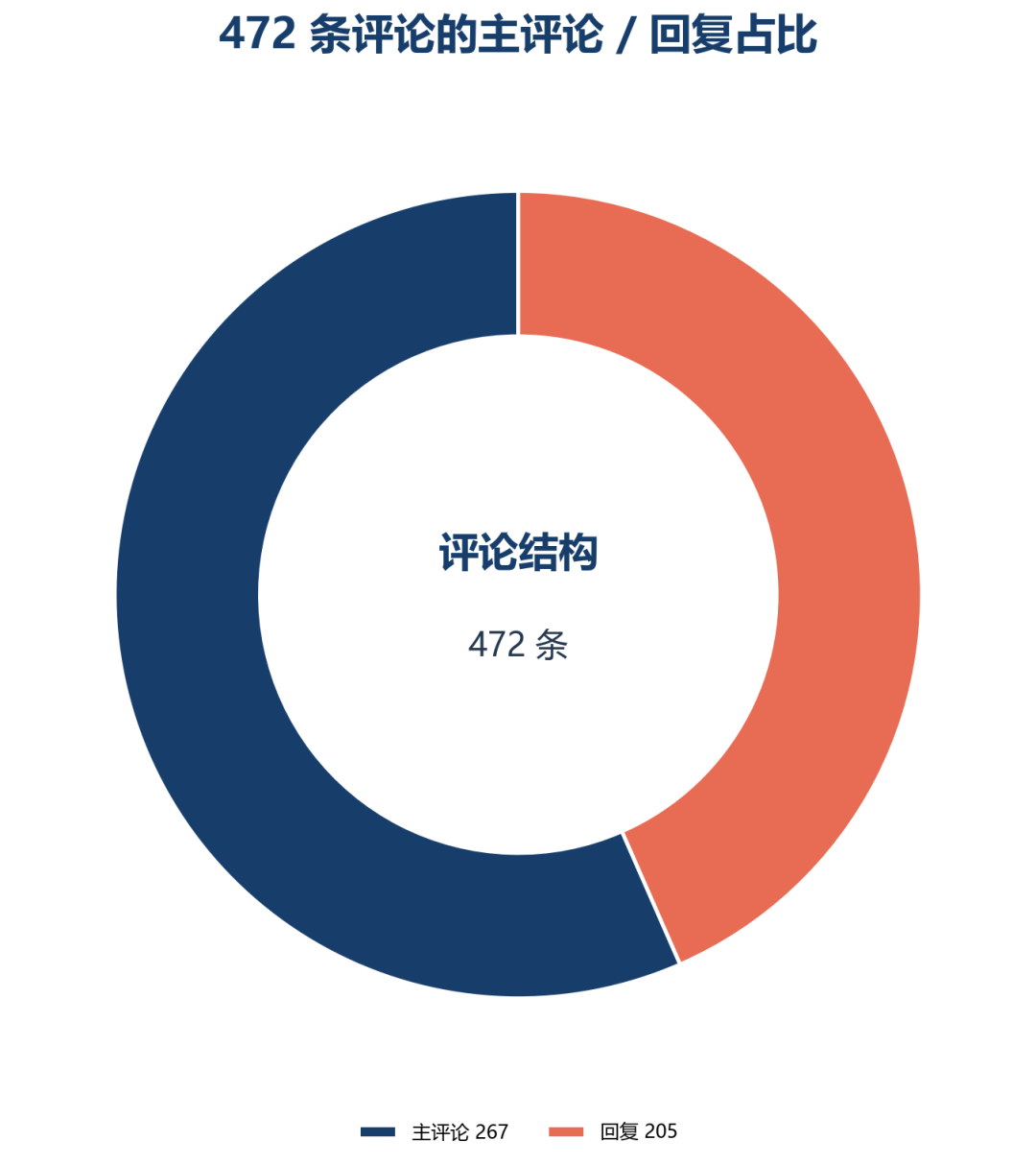
从样本观感上看,负面和质疑类评论占明显多数。
大家主要在争论什么
表面上看,大家在讨论“智能问数到底行不行”;但把评论归并后,真正反复出现的是五类问题:
1. 数据基础是否支撑
这是出现频率最高、共识也最强的一类。
典型评论:
chatbi两个巨大瓶颈,一是数据基座不行,garbage in garbage out...数据治理没做好,直接用肯定不行数据基础没做好,恐怕难以有成效
这类评论的意思很明确:
如果底层数据本来就是乱的,智能问数不会把乱数据变成好答案,只会更快地输出错误。
2. 语义层、指标体系、口径定义是否成熟
很多评论把问题进一步往上推了一层:即使原始数据能拿到,也不代表能问得对。
典型评论:
最关键的是数据治理和语义建模绝大多数都卡在指标化了,目前AI问数只能建立在指标体系上领导要的数据都是天马行空,你让负责业务的人来都得听半天才知道领导要什么口径的数据
这里的核心不是 SQL 能不能生成,而是:
- 指标是不是定义清楚了
- 业务口径是不是统一了
- 问题是否能被结构化表达
如果这些问题没先解决,模型越强,错得越像对的。
3. 准确率与信任成本能否承受
这类评论的共识也非常强。
典型评论:
数据不对的信任危机导致chatbi没有推广的可能性领导预期才是最麻烦的,上来就是mvp版本准确率先做到95%吧80%到95%要付出多少实施代价?
智能问数和普通 AI 助手最大的区别在于:
它一旦出错,用户很难把它当“灵感工具”,而会直接把它当“不可信”。
也就是说,这类产品对准确率的要求,不是“能用就行”,而是接近“不能明显出错”。 而要从 80% 到 95%,往往不是模型调一调,而是大量治理、建模、规则、校验和组织协作成本。
4. 用户真实需求是不是“自由提问”
这批评论里有一个很重要的分歧点:很多人并不认为“自由问数”是真需求。
典型评论:
这个东西本身,就有点伪需求,更多是技术研发侧视角出发的东西我觉得大部分公司取数并不是问题。有问题的是数据基建大多数时候我只需要几个数字而已。过度设计了
这些用户认为客户可能更需要:
- 已定义口径下的快速取数
- 固定场景下的高置信回答
- 看板解释、异常说明、经营建议
如果产品从一开始就押注“开放式自然语言分析”,很容易高估真实需求。
5. ROI 与组织推动是否划算
不少评论其实已经不再纠结技术,而是在问:
为了做成这件事,企业要付出的组织成本值不值?
典型评论:
很多公司都在做,但是都没做好,这个暂时只是一个噱头只是纯技术驱动的项目...那就是ppt项目,政绩项目技术销售一个很重要的工作是,降低客户对AI的不切实际预期
换句话说,很多项目不是死在模型效果,而是死在:
预期过高
场景定义过宽
业务部门不配合
落地周期过长
交付代价远高于感知价值
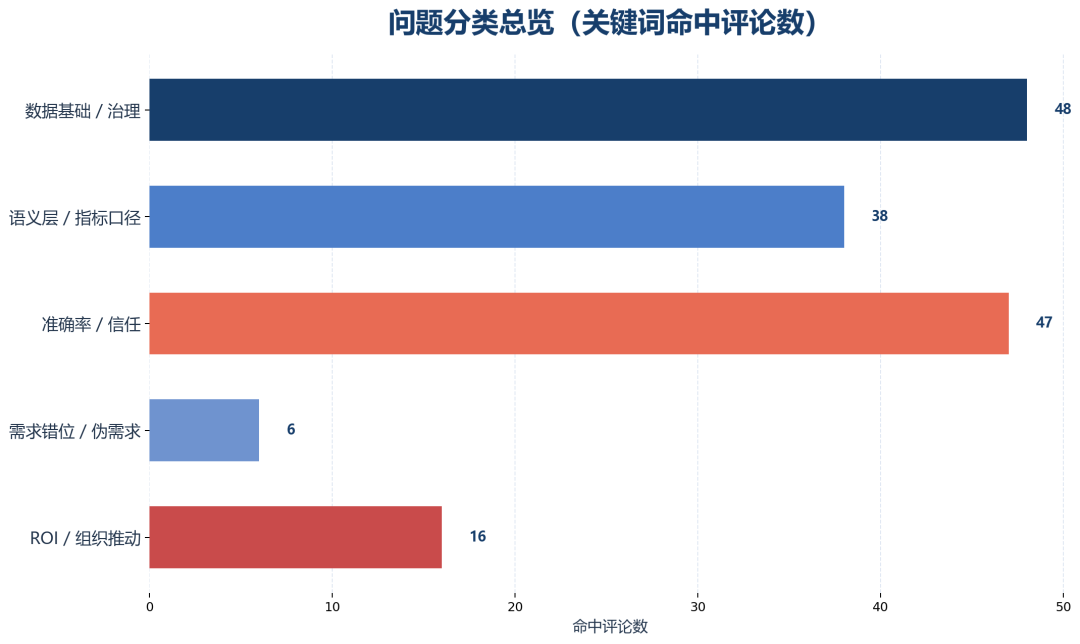
为什么大家普遍觉得“难落地”
如果把上面的讨论压缩成一句更本质的话:
智能问数难落地,不是因为“模型不够聪明”,而是因为它正好落在一个对企业基础能力要求很高的交叉点上。
这个交叉点同时要求:
- 数据层能用
- 指标层清晰
- 业务语言可解释
- 用户知道自己要问什么
- 系统能提供可信答案
- 企业愿意承担治理和迭代成本
而现实是,大多数企业在这六件事上不会同时成立。
所以评论里才会反复出现一种判断:
不是问数没有价值,而是多数企业还不具备把它做好所需要的前置条件。
这也是为什么很多从业者会把问题重新定义为:
- 真正难的不是
text2sql - 真正难的是把企业的数据与业务表达整理到可以被稳定消费
哪些反对意见最有分量
不是所有“唱衰”都一样有价值。 这批数据里,最有分量的反对意见主要来自三类人:
1. 做过实施或项目交付的人
这类评论通常不会停留在“我觉得没用”,而会明确指出卡点:
- 数据基础
- 指标体系
- 实时性
- 复杂问题
- 成本与准确率的 trade-off
这类评论可信度高,因为它们讲的是落地阻力,不是情绪判断。
2. 懂数据分析和 BI 体系的人
这类人经常会指出一个关键矛盾:
过去数据分析做不好的事情,不会因为加了 AI 就自动变好。
这类观点的重要性在于,它能防止团队把“分析问题”误判成“模型问题”。
3. 对业务需求很敏感的人
这类评论主要表达:
- 用户不一定真的想“自由提问”
- 很多需求本质是固定经营分析
- 很多老板也说不清自己的口径
这类反馈的价值在于,它能帮助产品从“技术可做”回到“用户真的需要什么”。
相对而言,单纯的“AI 不行”“都是噱头”这类评论虽然有情绪信号,但单独看并不构成决策依据。
是否意味着“智能问数没有价值”
讨论不意味着“智能问数没有价值”。
更准确的说法是:
“通用型、开放式、替代分析师想象的智能问数”价值被高估了;但“窄场景、强约束、半自动、可校验”的智能问数仍然有价值。
这类价值通常出现在以下场景:
1. 已有较成熟指标体系的企业
如果企业已经完成了较好的数据治理、指标口径统一、语义层建设,那么智能问数可以作为:
- 一层更自然的查询入口
- 一个管理者自助获取经营数据的入口
- 一个看板解释与辅助分析入口
2. 固定问题、固定口径、固定数据源的场景
例如:
- 销售日报问答
- 库存异常说明
- 运营活动复盘
- 财务经营指标追问
这些场景的共同点是:
- 问题范围可控
- 结果有校验基准
- 用户容忍度更高
3. 人机协同而不是纯自动替代
更现实的形态不是“业务完全自助分析”,而是:
- AI 帮忙理解问题
- AI 帮忙路由到正确指标或服务
- AI 帮忙解释结果
- 关键结论保留人工校验或复核
这比“直接替代分析师”更容易落地,也更符合评论里的真实反馈。
基于这些数据,更值得做的方向
基于讨论的数据,整理出四类有价值的方向。
方向 1:从“自由问数”改成“场景化经营分析助手”
不是让用户问任何问题,而是围绕少数高频经营场景提供:
- 标准问题模板
- 结构化追问
- 指标解释
- 异常归因建议
这类方向更符合评论里的真实需求,也更容易建立信任。
方向 2:从“SQL 生成”改成“语义层和指标治理增强”
这批评论已经反复证明:
很多企业真正缺的不是一个更会写 SQL 的模型,而是:
- 指标定义
- 元数据标注
- 业务语义映射
- 数据血缘和口径管理
所以比起做一个“更聪明的问数入口”,做“让问数能成立的前置层”可能更有价值。
方向 3:从“替代分析师”改成“分析提效工具”
更现实的价值不一定是让业务直接用,而是帮助:
- 数据分析师
- BI 团队
- 经营分析团队
去更快完成:
- 查数
- 对口径
- 找相关指标
- 生成解释草稿
- 形成标准回复
这类场景对准确率的容忍方式不同,也更容易获得早期正反馈。
方向 4:把能力做成咨询/交付/MVP 验证服务,而不是先做大而全产品
从这批评论看,真正的难点高度依赖企业内部情况。 这意味着,一个通用平台不是当前最优入口。
更现实的切法可能是:
- 先做一个窄场景验证服务
- 先帮客户梳理指标和语义层
- 先在一两个业务问题上做出可验证效果
- 再决定哪些能力值得产品化
这和本项目本身的定位也一致:先做机会验证工作台,而不是先做全功能平台。
结语
如果把这 472 条评论压缩成一句真正能指导下一步行动的话,我会这样写:
智能问数不是伪命题,但“开放式通用问数”大概率是被过度承诺的命题。
对一个想基于这类机会继续做产品的人来说,这批评论给出的最重要启发是:
- 不要把它做成一个“什么都能问”的万能入口
- 应该把它做成一个“在特定场景里能稳定给出可信答案”的分析助手
如果再进一步收敛成一句更适合产品决策的话:
真正更值得做的,不是“通用智能问数平台”,而是“围绕具体业务场景的、带语义层和规则约束的分析助手”。
这才更接近这批评论背后的真实需求,也更接近可落地的机会。
更多智能问数相关技术:
智能问数技术路线与选型
企业 Agent 的统一语义模型方案