随着人工智能新范式时代的到来,嵌入模型已成为信息检索、语义匹配和知识管理领域不可或缺的基石。然而,面对众多模型及其复杂特性,如何科学、高效地运用它们,是许多开发者和研究者面临的共同课题。
科学使用嵌入模型的核心在于:① 理解其架构差异,采用匹配的查询策略;② 掌握并利用MRL等先进技术,在成本与效果间取得最佳平衡;③ 构建“召回+重排”的系统化流程,确保最终结果的精准性。下文以 BGE-M3 和 Qwen3-Embedding为代表,介绍不同架构嵌入模型的特点和用法。
一、 主流嵌入模型
1. BGE-M3:“双塔编码器” (Encoder-based)
- 架构原理:
基于BERT类的双向编码器(Encoder),采用双塔(Bi-Encoder)结构进行对比学习。查询和文档被独立编码到同一向量空间,通过拉近相关对、推远不相关对进行优化。
- 向量来源:
通常取[CLS] token的输出向量,该向量融合了整个文本的双向上下文信息。
- 核心特点:
多功能性 (Multi-Functionality)。一次计算即可生成稠密、稀疏、多向量三种表示,天然支持混合检索,鲁棒性极强。由于其训练方式,它对自然语言查询有很好的泛化能力,无需额外指令。
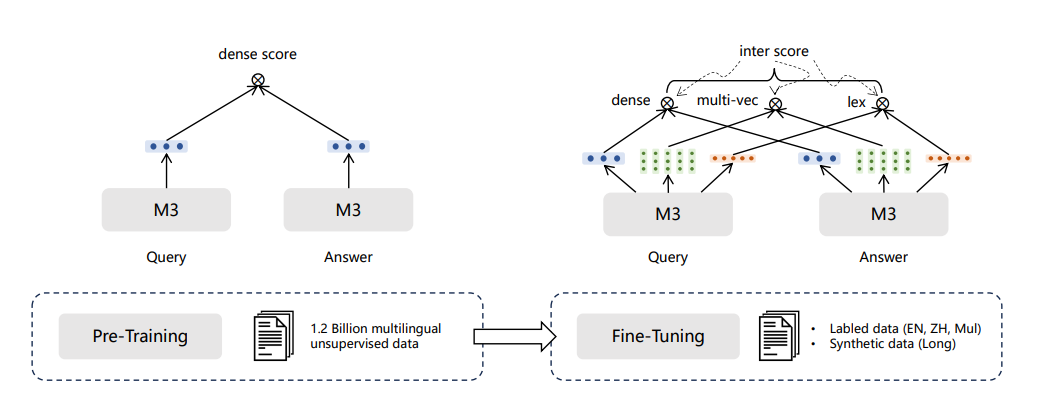
图1 双塔模型(Bi-Encoder)结构示意图
2. Qwen3-Embedding:“因果解码器” (Decoder-based)
- 架构原理:
基于Qwen3大语言模型的单向解码器(Decoder),通过指令微调使其胜任表示学习任务,这个特点决定了需要增加指令提升准确性。
- 向量来源:
通常取[EOS](文本结束符)token的输出向量,该向量编码了其前面所有文本的信息。
- 核心特点:
指令感知 (Instruction-Aware) 和 MRL (Matryoshka Representation Learning)。
- 指令感知
模型能理解并根据查询前缀中的“指令”来调整其行为,使其在特定任务上表现更佳。
- MRL
这是其最具变革性的技术之一,我们将在下一节详述。
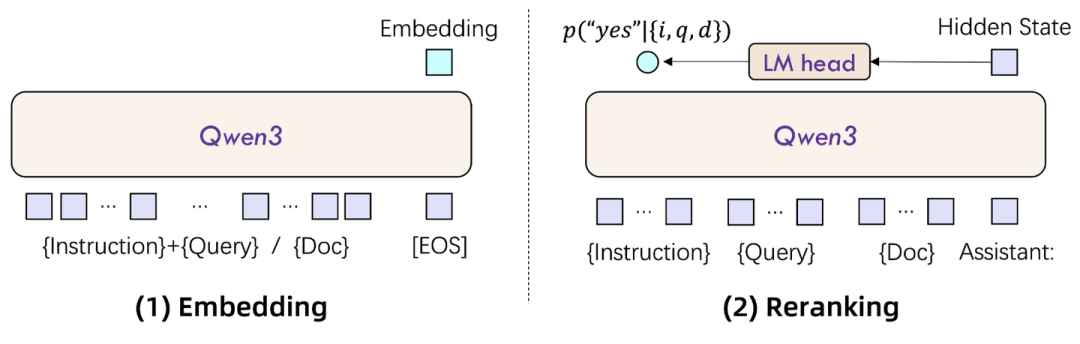
图2 Qwen3-Embedding(左)与 Qwen3-Reranker(右)的模型架构
二、 MRL(套娃表示学习)的原理与用法
MRL是Qwen3-Embedding等新一代模型实现“可变维度”的秘密武器,改变了向量维度、成本和效果的认知。
1. MRL是什么?—— 俄罗斯套娃的比喻
想象一个俄罗斯套娃:一个4096维的向量是最大的娃娃,它包含了最完整的信息。当你截取它的前2048维时,你得到的不是一个“残缺”的向量,而是第二个、稍小但同样完整且高质量的2048维向量(娃娃)。以此类推,前512维、前256维都是一个个更小但依然功能完备的向量。
这意味着:你只需要生成一次高维向量,就可以通过简单的“截断”操作,自定义输出维度。
2. MRL的训练原理:多尺度联合损失
普通模型的向量不能被随意截断,因为信息是均匀散布在所有维度上的。MRL通过一种特殊的训练机制解决了这个问题:
多维度切片
在训练过程中,模型生成一个全维度(如4096d)的向量后,MRL会虚拟地将其截断成多个版本(如2048d, 1024d, 512d...)。
计算联合损失
模型的总损失函数不是只在最终的4096维上计算一次,而是所有这些维度版本损失的加权总和。 Loss_Total = w1 * Loss(V_4096) + w2 * Loss(V_2048) + ...
信息分层编码
这种联合优化的方式,“逼迫”模型学会将信息按重要性分层。为了让所有维度的损失都尽可能小,模型会自发地:
将最核心、最宏观的语义信息编码到向量的最前端(如前256维)。
将更精细、更具体的语义信息编码到向量的中间部分。
将最细微的语义差别编码到向量的末端。
结果就是,截断后的低维向量保留了最重要的语义信息,保证了其高质量和可用性。
3. MRL的科学用法:成本与效果的完美平衡
MRL的价值在于让你能够在RAG系统的不同阶段,使用不同维度的向量,以实现最优的资源配置。
大规模索引阶段(追求效率和低成本)
操作:
对海量文档进行编码时,生成4096维的全维度向量并存储。但在构建向量数据库索引时,只使用其前512维(或更低)进行索引。
- 收益:
极大地降低了存储成本和内存(RAM)占用,同时大幅提升了检索速度(QPS)。
高精度重排阶段(追求极致精度)
操作:
当使用512维索引快速召回Top-100个候选文档后,从存储中取出这100个文档对应的全维度(4096维)向量。然后,使用查询的4096维向量与这100个全维向量进行一次“向量内部的”高精度重排序。
- 收益:
这个步骤计算量极小,但能利用全维度信息进行更精确的筛选,为后续的Cross-Encoder重排模型提供质量更高的输入。
三、 如何科学使用嵌入模型
1. 通用准则(两者均适用)
合理分块
文本块大小为300-500字符,重叠10%-20%,并在块首附上标题等元数据。
两阶段架构
强烈推荐采用“向量召回 (Retrieval) + 模型重排 (Reranking)”的两阶段架构。
混合检索
结合语义(稠密)和关键词(稀疏/BM25)检索,能显著提升系统在各种查询类型下的鲁棒性。
2. 不同模型的优化查询策略
A. BGE-M3:混合检索
数据入库
对文档进行编码,同时获取并存储其稠密向量(dense_vecs)和稀疏向量(sparse_vecs)。
查询处理:
- 输入
直接使用用户的自然语言查询,无需添加任何前缀。
- 编码
同样获取查询的稠密和稀疏向量。
混合检索:
分别计算稠密相似度得分和稀疏匹配得分。
通过加权融合(例如
0.4 * dense_score + 0.6 * sparse_score)得到最终排序,召回Top-K(如K=50)个候选。
重排:
将这K个候选送入rerank模型(例如:bge-reranker-v2-m3)模型,得到最终的Top-N(如N=5)个最相关结果。
B. Qwen3-Embedding:基于MRL的效能优化方案
数据入库(利用MRL):
对所有文档,使用Qwen3-Embedding编码生成全维度(如4096d)向量,并将其完整存储(保存在redis或关系型数据库)。
在构建向量数据库索引(保存在向量数据库)时,仅使用该向量的前512维。
查询处理:
- 输入
强烈建议将用户查询构造成指定的指令模板。
Instruct: Given a web search query, retrieve relevant passages that answer the queryQuery: {用户的原始问题}- 编码
对整个模板进行编码,生成查询的全维度(4096d)向量。
MRL两步召回:
- 第一步:粗召回(低维、高速)
使用查询向量的前512维,在512维的索引中快速召回Top-K(如K=100)个候选。
- 第二步:精排序(高维、精准)
取出这100个候选对应的全维度(4096d)向量,与查询的全维度(4096d)向量进行一次更精确的相似度计算和排序,筛选出Top-K'(如K'=30)。
重排:
将这K'个候选送入Qwen3-Reranker模型,得到最终的Top-N个结果。
四、 为什么重排模型 (Reranker) 能提升准确率
重排模型之所以能大幅提升最终的准确率,其核心原因在于它采用了与嵌入模型(召回模型)完全不同且更为精细的计算范式——跨编码器(Cross-Encoder)。
交互方式的根本不同:
- 召回阶段 (Bi-Encoder):
召回阶段,查询(Query)与文档(Document)独立编码,彼此不交互;最终对两个向量做一次相似度计算(如余弦/内积)。这类方式可离线预编码文档、易于建立 ANN 索引,速度极快,适合大规模“海选”。
- 重排阶段 (Cross-Encoder):
重排阶段,将每个候选文档与同一个查询拼接到同一上下文中,由同一个模型对每个「Query–Document」联合输入计算相关性分数。输入示例:
— Encoder-only/BGE-Reranker 风格:[CLS] Query [SEP] Document [SEP]
— Decoder-only/Qwen3-Reranker 风格:Instruct: …\nQuery: …\nDocument: …(合并为单段上下文)
Cross-Encoder 计算更细致,但无法离线预编码文档、成本与候选数线性增长,因此通常只用于对 Top-K(如 20–50)候选进行重排。
- 注意:Bi-Encoder/Cross-Encoder 是“工作方式/交互范式”,与模型架构(encoder-only、decoder-only)无关。
深度交互带来的优势:
- 全层注意力机制
在Cross-Encoder内部,查询中的每一个词都可以和文档中的每一个词,通过多层自注意力(Self-Attention)机制进行深度、充分的交互。模型可以捕捉到极其细微的语义关联、词序依赖、甚至是否定关系。
- 更强的判别能力
例如,对于查询“哪些笔记本电脑_不带_小键盘?”,Bi-Encoder可能因为“笔记本电脑”和“小键盘”的语义接近而召回很多带小键盘的文档。但Cross-Encoder在拼接输入后,能精准地理解“不带”这个否定词的作用,从而给那些真正不带小键盘的文档打上高分,给带的打上低分。
计算与效果的权衡:
Cross-Encoder的计算量巨大,因为它需要对每个(查询-文档)对都进行一次完整的模型前向传播。如果直接用它在全库中检索,将会慢到无法接受。
因此,“Bi-Encoder快速召回 + Cross-Encoder精准重排” 的两阶段架构,完美地结合了二者的优点:用Bi-Encoder的速度保证了“找得到”(高召回率),再用Cross-Encoder的精度保证了“排得准”(高精确率)。
五、 常见误区与总结
- 误区一:混用查询策略
给BGE-M3加指令,或者不给Qwen3-Embedding加指令,都可能会导致性能下降。
- 误区二:未使用MRL的全部潜力
只用Qwen3-Embedding的低维或高维,而没有结合使用,就浪费了其在成本和效果之间动态平衡的巨大优势。
- 误区三:忽略重排模型
只依赖向量召回的排序结果,通常是不够精准的,尤其是在处理复杂或模糊的查询时。
- 误区四:Qwen3-Embedding用错池化方式
务必确认框架使用的是[EOS] token pooling,而非默认的mean或[CLS] pooling。
最终结论:科学使用嵌入模型的本质是因地制宜。理解并尊重模型的设计原理,将BGE-M3的多功能混合检索和Qwen3-Embedding的指令感知与MRL等核心技术,无缝地融入到“召回+重排”的系统化流程中,才能构建出真正高效、精准且经济的智能查询系统。