本文讲解通用逼近定理(Universal Approximation Theorem)是如何证明出来的。
通用逼近定理指的是:一个包含单层隐藏层、并使用非线性激活函数(如Sigmoid)的神经网络,只要其隐藏层包含足够多的神经元,就可以以任意精度逼近任何一个定义在有界闭集上的连续函数。
下面的证明过程使用直观的逻辑而不纠结于复杂的数学公式,力求快速理解。
这个证明的精髓在于“构造性”,即证明我们可以用神经网络“搭建”出任何我们想要的函数形状。整个证明可以优雅地分为三个核心步骤:
第一步:单个神经元能做什么?—— 创造一个“平滑的阶梯”
首先,我们来看一个最基本的组件:一个带有 Sigmoid 激活函数的神经元。Sigmoid 函数的形状是一个平滑的“S”曲线,它将任意输入值映射到 (0, 1) 之间。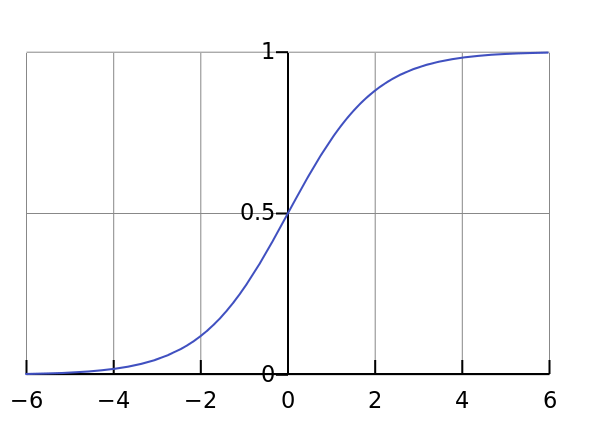 一个神经元的计算公式是
一个神经元的计算公式是 output = σ(w * x + b)。通过调整权重 w 和偏置 b,我们可以控制这个“S”曲线:
- 调整权重
w:可以改变“S”曲线的陡峭程度。w越大,曲线在中间部分就越像一个垂直的“阶梯”;w越小,曲线越平缓。 - 调整偏置
b:可以左右平移这个“S”曲线的位置。
所以,一个神经元的核心能力是:在数轴上的任意位置,创造一个任意陡峭的、平滑的阶梯(或者叫“开关”函数)。
第二步:两个神经元能做什么?—— 创造一个“凸起”
这是证明中最巧妙的一步。如果我们只有一个“阶梯”,似乎做不了什么复杂的事情。但如果我们有两个呢?
想象一下,我们用一个神经元创造一个向上的阶梯(权重为 w),再用另一个神经元创造一个稍微向右平移一点的、向下的阶梯(权重为 -w)。然后,我们将这两个神经元的输出加起来。
会发生什么?
1. 在第一个阶梯跃升之前,两个输出都接近0,相加也接近0。
2. 在两个阶梯之间,第一个输出接近1,第二个输出接近0,相加结果接近1。
3. 在第二个阶梯跃升之后,第一个输出接近1,第二个输出接近-1,相加结果又回到了0。
通过这种方式,我们成功地用两个神经元创造了一个“凸起”或“门”函数(bump function)。可通过下图直观感受(具体代码在文末,复制到本地可以直接运行)。
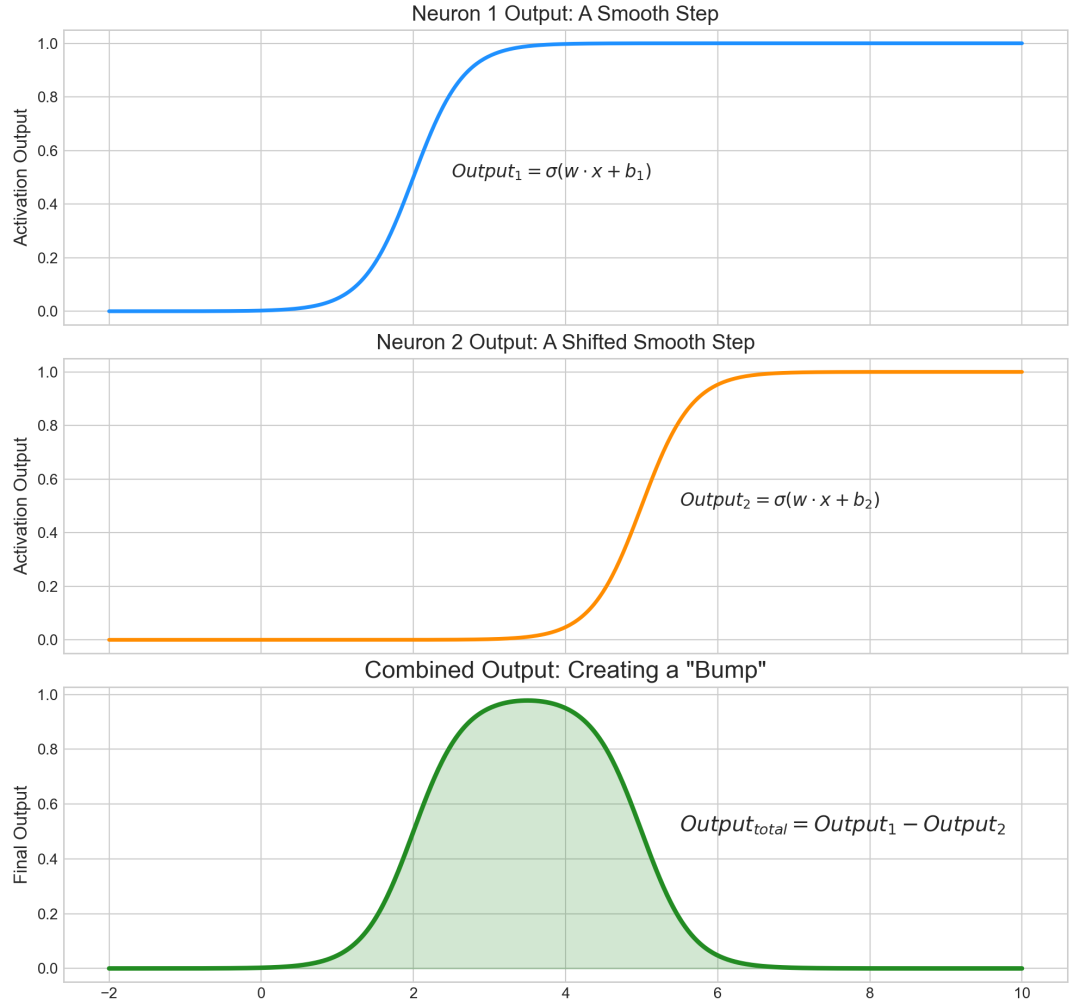
更棒的是,通过精细地调整这两个神经元的权重和偏置,我们可以自由地控制这个“凸起”的位置、宽度和高度。它就像一块可以随意定制的“乐高积木”。
第三步:无数个“凸起”能做什么?—— 铺成任何函数
现在我们拥有了可以随意定制的“凸起”积木,最后一步就顺理成章了。
任何一个定义在有界闭集上的连续函数,无论它多么崎岖不平,我们都可以想象用一系列非常窄的“长方形”去近似它。这和微积分中用黎曼和(Riemann sum)求定积分的思想如出一辙。
我们的神经网络就可以做同样的事情:
- 我们使用大量的神经元对(每对两个神经元)来制造大量的、紧密排列的“凸起”。
- 每个“凸起”对应一个“长方形”,其位置、宽度和高度都经过精心设计,以匹配目标函数在该位置的形状和值。
- 通过将所有这些“凸起”线性叠加(在输出层完成),我们就能以任意高的精度“铺出”或“拼凑”出任何连续函数的形状。
隐藏层的神经元越多,我们能制造的“凸起”就越多、越精细,对目标函数的近似就越精确。这就完美地解释了定理中“只要其隐藏层包含足够多的神经元”这一关键条件。
总结
所以,通用逼近定理的证明核心可以概括为:
单个神经元能制造一个可控的“平滑阶梯”。
两个神经元组合可以制造出一个位置、宽度、高度都可控的“凸起”(我们的基本构造单元)。
足够多的神经元可以制造出足够多的“凸起”,像搭积木一样,以任意精度搭建出任何连续函数的形状。
这个证明告诉我们,从理论上讲,单层神经网络具有无限的潜能。但它也有两大局限性需要注意:
- 存在性而非构造性:定理只证明了满足条件的网络存在,但没有告诉我们如何通过训练找到这些合适的权重和偏置。寻找最优参数是深度学习训练算法(如梯度下降)要解决的问题。
- 宽度 vs. 深度:定理表明一个“足够宽”的单层网络就够了,但实践中发现,深度网络(多层隐藏层)在学习复杂模式时通常比浅层网络更高效、更强大。这是因为深度网络能学习到更具层次化的特征抽象,而不是仅仅用“凸起”去“死记硬背”函数形状。
下面是可以直观查看效果的代码:
import numpy as npimport matplotlib.pyplot as plt
# 使用一个美观的绘图风格plt.style.use('seaborn-v0_8-whitegrid')
def sigmoid(x): """Sigmoid 激活函数"""
return 1 / (1 + np.exp(-x))
# 1. 定义输入范围# np.linspace 从 -2 到 10 之间生成 500 个点
x = np.linspace(-2, 10, 500)# 2. 定义两个神经元的参数
# 这两个神经元都在同一个隐藏层w = 3.0 # 权重 w, 控制阶梯的陡峭程度
b1 = -6.0 # 偏置 b1, 控制第一个阶梯的位置b2 = -15.0# 偏置 b2, 控制第二个阶梯的位置 (更靠右)
# 计算第一个神经元的输出# 它在 x = 2 附近从 0 跃升到 1
neuron1_output = sigmoid(w * x + b1)# 计算第二个神经元的输出
# 它在 x = 5 附近从 0 跃升到 1neuron2_output = sigmoid(w * x + b2)
# 3. 在输出层将两个神经元的输出结合# 通过 (Neuron1_output * 1) + (Neuron2_output * -1) 来实现
# 这等价于两个输出相减combined_output = neuron1_output - neuron2_output
# 4. 绘图# 创建一个包含 3 个子图的画布, 并且共享 x 轴
fig, axs = plt.subplots(3, 1, figsize=(10, 12), sharex=True)# --- 子图 1: 第一个神经元 ---
axs[0].plot(x, neuron1_output, color='dodgerblue', linewidth=2.5)axs[0].set_title('Neuron 1 Output: A Smooth Step', fontsize=14)
axs[0].set_ylabel('Activation Output', fontsize=12)axs[0].text(2.5, 0.5, r'$Output_1 = \sigma(w \cdot x + b_1)$', fontsize=12)
axs[0].grid(True)# --- 子图 2: 第二个神经元 ---
axs[1].plot(x, neuron2_output, color='darkorange', linewidth=2.5)axs[1].set_title('Neuron 2 Output: A Shifted Smooth Step', fontsize=14)
axs[1].set_ylabel('Activation Output', fontsize=12)axs[1].text(5.5, 0.5, r'$Output_2 = \sigma(w \cdot x + b_2)$', fontsize=12)
axs[1].grid(True)# --- 子图 3: 组合输出 ---
axs[2].plot(x, combined_output, color='forestgreen', linewidth=3)axs[2].fill_between(x, combined_output, color='forestgreen', alpha=0.2)
axs[2].set_title('Combined Output: Creating a "Bump"', fontsize=16)axs[2].set_xlabel('Input (x)', fontsize=12)
axs[2].set_ylabel('Final Output', fontsize=12)axs[2].text(5.5, 0.5, r'$Output_{total} = Output_1 - Output_2$', fontsize=14)
axs[2].grid(True)# 自动调整布局并显示图像
plt.tight_layout plt.show