你是否曾疑惑,为什么 vLLM 等顶尖推理框架,能用同样一张显卡,实现比别人高出数倍的吞吐量?
答案,就藏在一项名为 PagedAttention 的革命性技术中。它并非一种新的注意力算法,而是一种堪称“黑魔法”的 KV 缓存管理机制。
PagedAttention 是一项革命性的内存管理技术,专为解决大语言模型(LLM)推理过程中的显存效率问题而设计。它并非一种新的注意力算法,而是一种创新的 KV 缓存(Key-Value Cache)管理机制。通过借鉴操作系统的核心思想,PagedAttention 从根本上改变了显存的分配与使用方式,使得在有限的显存下实现更高的系统吞-吐量成为可能,已成为 vLLM 等业界领先推理框架的基石。
核心问题:传统 KV 缓存管理的双重困境
要理解 PagedAttention 的价值,必须先明确它所解决的痛点。在传统推理框架中,系统为每个请求的 KV 缓存分配显存时,面临着以下无法回避的困境:
基于“最大长度”的预分配模式:由于无法预知请求的最终生成长度,系统必须采取一种保守策略——为每个请求预先分配一块能够容纳预设最大序列长度(max_sequence_length)的连续显存空间。
由此产生的巨大浪费:
- 内部碎片化(Internal Fragmentation)绝大多数请求的实际长度远小于预设的最大长度。例如,系统为请求预留了 4096 个词元(Token)的空间,但请求实际只使用了 500 个。那么多出的 3596 个词元的空间就被永久性浪费了,因为它们位于这个已分配的连续块内部,无法被其他请求利用。
- 外部碎片化(External Fragmentation)随着不同长度的请求不断创建和释放,整个显存空间会变得支离破碎,形成大量不连续的“内存空洞”。即使总剩余显存充足,也可能因为找不到一块足够大的连续空间而无法服务新请求。
据论文统计,这两种碎片化问题合计可导致 60% 至 80% 的宝贵显存被无效占用。
恰当的比喻:传统方式就像去餐厅,无论您几人用餐,都必须为您预定一个能容纳 20 人的大包间。如果您只来了三个人,剩余 17 个座位就全程空置浪费。
核心原理:借鉴操作系统的“分页”思想
PagedAttention 的设计灵感直接来源于现代操作系统管理内存的虚拟内存(Virtual Memory)和分页(Paging)机制。它彻底颠覆了“预分配连续空间”的模式。
其核心机制包含三点:
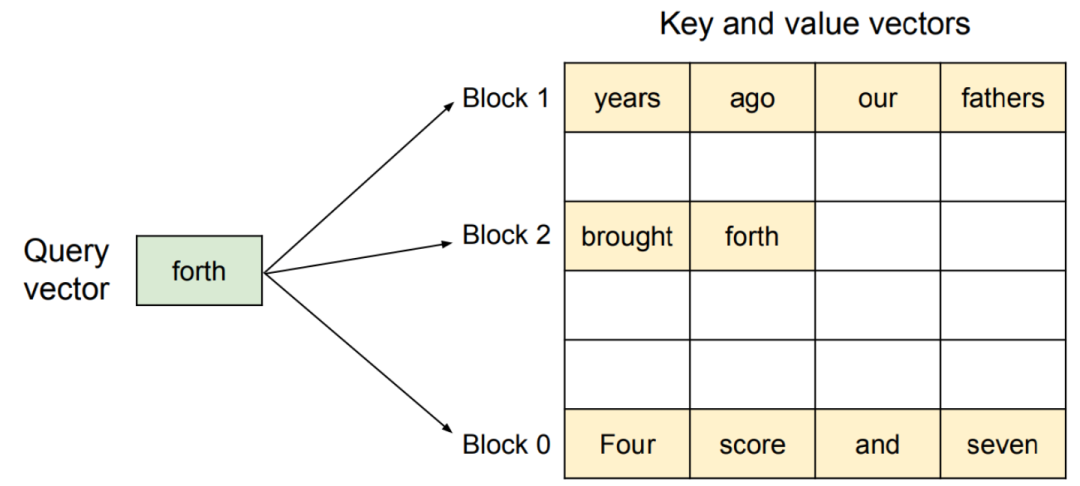
块化(Blocking/Paging):系统不再将显存视为需要切割的大块连续空间。而是预先将其划分为成千上万个固定大小、不连续的物理块(Blocks 或 Pages),形成一个统一的“内存池”。
逻辑与物理分离:对于一个请求而言,它的 KV 缓存数据在逻辑上仍然是按词元顺序连续排列的。但在物理存储上,这些数据被存放在内存池中任意离散的物理块里。
块表(Block Table):为了连接逻辑与物理,系统为每个请求维护一个块表。这个表就像一个地址目录或索引,负责将逻辑上的词元位置映射到其所存储的物理块地址。
恰当的比喻:PagedAttention 就像使用活页本写文章。文章的每一页(物理块)可以随意安放,您只需要维护一个目录(块表)来记录正确的阅读顺序即可。这与必须找到一本连续空白页的传统笔记本形成了鲜明对比。
关键澄清:理论占用 vs 实际分配
这是一个至关重要的概念区分,也是我们讨论中的核心点:
- PagedAttention 不会改变 KV 缓存的“理论占用空间”一个包含 N 个词元的序列,其 KV 缓存所需存储的信息量是固定的,这是由模型架构决定的物理下限。
- PagedAttention 极大地降低了“实际分配空间”,使其无限接近于“理论占用空间”。
| 对比维度 | 传统方式(无 PagedAttention) | vLLM(使用 PagedAttention) |
|---|---|---|
| 理论占用 | N 个词元所需的空间 | N 个词元所需的空间 |
| 实际分配 | max_sequence_length 个词元所需的空间 | N 个词元所需的空间 |
| 浪费 | max_sequence_length - N | 几乎为零 |
PagedAttention 的“节省”并非源于对数据的压缩,而是源于对内存管理哲学的革新,它消除了因“为未来不确定性预留空间”而产生的巨大成本。
运行模式的根本转变
讨论的最后,精准地概括两种模式的运行差异:
传统方式(预分配):
- 分配时机请求开始前,一次性、整体性地分配。
- 分配依据固定的最大序列长度。
- 核心思想为最坏情况预留(Worst-Case Reservation)。
PagedAttention 方式(动态分配):
- 分配时机运行时,随着每个词元的生成而逐步、按需地分配。
- 分配依据请求当前实际处理的词元数量。
- 核心思想即用即付(Pay-As-You-Go)。
在 vLLM 等框架中,启动时会根据 gpu_memory_utilization 参数创建一个全局的物理块池。之后的所有内存操作都是在这个池中进行的动态“取”与“还”,而非为每个请求单独规划和预留大块空间。
结论
PagedAttention 通过引入操作系统的分页机制,实现了对 LLM 推理中 KV 缓存的精细化、动态化管理。它并非减少了KV缓存的理论大小,而是通过几乎完全消除内存碎片和不必要的预留,使得实际物理内存占用无限逼近理论值。这一根本性的转变,直接带来了内存利用率的大幅提升和系统吞吐量的显著增加,是当前大模型服务部署领域的一项关键性优化技术。