现在研究 Agent 的开发者很多,多数开发者对 Agent 的研究是基于 个人Agent 的实现,比如 OpenClaw、Hermes-Agent。然而,企业 Agent 的一些实现机制和个人Agent是不同的,尤其是记忆。
今天我们分析一下企业 Agent 需要怎么样的记忆机制,供需要企业 Agent 落地的团队和开发者参考。
本文中的“企业 Agent 记忆”不是狭义的 Agent 私有长期记忆,而是企业 Agent 在执行任务时可访问、可引用、可更新、可审计的一整套记忆与上下文基础设施,包括会话状态、候选记忆、组织知识、权威业务系统、关系图谱、流程资产和审计日志。
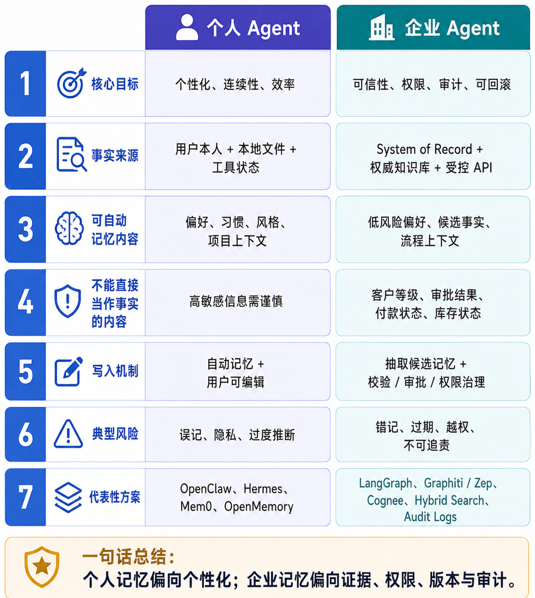
总体来说,个人智能体的记忆,偏“个性化”和“连续性”;企业智能体的记忆,偏“证据、权限、版本、审计和可回滚”。
也就是说,个人 Agent 记住“我喜欢简洁回复“、“默认 TypeScript”,就可以带来比较好的使用体验;但是企业 Agent 不能随便把“用户说客户甲是 VIP”当成事实。真正的客户等级必须来自 CRM、合同、订单或审批系统。
我们首先梳理当前 Agent 常见的记忆类型,然后分析个人 Agent 和企业 Agent 分别需要怎么样的记忆机制。
Agent 的记忆类型
当前的 Agent 记忆,根据记忆对象和使用场景,大致可以分为下面 7 类。
另外,从信息来源看,Agent 记忆也可以分为2类:
- 内生记忆:来自 Agent 与用户、任务、工具交互后的沉淀,比如会话历史、用户偏好、历史任务、自动更新的 skills。
- 外部记忆:来自知识库、业务系统、文档库、CRM、ERP 等外部系统。知识库 RAG 检索可以视为 Agent 的一种“外部检索型记忆 / 参考记忆”,但它不是 Agent 自身长期记忆。
| 记忆类型 | 作用 | 典型实现 | 风险 |
|---|---|---|---|
| 短期记忆 / 会话记忆 | 记住当前对话、当前任务状态 | message history、checkpoint、session store | 上下文过长、旧信息干扰 |
| 用户画像记忆 | 记住偏好、习惯、沟通风格 | saved memories、profile facts、Markdown、JSON | 误记、过度推断、隐私 |
| 情节记忆 / Episodic memory | 记住过去发生过什么,比如上次讨论过某个项目 | conversation logs、timeline、semantic search | 检索到旧的、过期的事实 |
| 语义记忆 / Semantic memory | 记住稳定的事实、项目背景、知识,比如某个项目使用 PostgreSQL 数据库 | fact extraction、structured fact store、knowledge base、vector index | LLM 抽取事实不可靠 |
| 实体 / 关系记忆 | 记住人、客户、项目、产品之间的关系 | knowledge graph、temporal graph | 冲突、时效性、权限 |
| 程序记忆 / Procedural memory | 记住“怎么做” | skills、runbooks、SOP、代码脚本 | 未测试流程被自动执行 |
| 审计记忆 / Audit memory | 记住 Agent 为什么这么做 | trace、tool logs、retrieval logs、approval logs | 若缺失,企业无法追责 |
近期受到关注的 OpenClaw、Hermes-Agent 智能体,以及 LangGraph 等开发框架,都会综合使用多种记忆方式。
下面是对主流 Agent 记忆相关方案的梳理。需要注意的是,这张表不是严格同层级的横向对比,而是对当前 Agent 记忆生态中常见组件的定位梳理。
| 方案 | 核心机制 | 个人智能体 | 企业智能体 |
|---|---|---|---|
| OpenClaw Memory | Markdown memory、daily notes、dreaming、memory search | 很适合本地个人助手 | 可用于小团队实验;企业需额外权限、审计和审批 |
| Hermes Agent Memory | MEMORY.md + USER.md + session search + learning loop | 很适合长期个人助手 | 自生成记忆 / 技能不能直接投产 |
| Mem0 | 自动抽取、用户 / 会话 / agent 多级记忆、hybrid retrieval | 很适合个人长期记忆和跨工具记忆 | 可用于低风险偏好或候选记忆;企业事实需校验 |
| OpenMemory | 项目级 coding memory、访问日志、可见性规则 | 很适合开发者个人 coding agent | 可作为工程团队工具,但需接企业 IAM / repo 权限 |
| Letta / MemGPT | core memory + archival memory,agent 自主读写 | 适合长期自维护 agent | 可作为 agent working memory;权威数据写入需治理 |
| LangGraph Memory | checkpoint + store,工程化状态管理 | 适合复杂个人 workflow | 很适合企业流程的 session state 和 long-term store 基础设施 |
| LlamaIndex Memory | static / fact / vector memory blocks | 适合文档型个人助手 | 适合企业 RAG agent,但 fact extraction 要当候选 |
| CrewAI Memory | LLM 自动分析 scope / category / importance | 适合 multi-agent 原型 | 企业慎用自动写入,需审批和审计 |
| AutoGen Memory | memory protocol,可自定义实现 | 灵活但需开发 | 适合自研企业 memory,但要自己补治理 |
| Zep / Graphiti | temporal knowledge graph、provenance、validity window | 适合复杂个人关系 / 长期项目 | 适合动态企业上下文和关系事实 |
| Cognee | graph + vector + connectors + ACL | 个人通常过重 | 适合组织级“公司大脑”和跨系统知识统一 |
| Honcho | 深层用户建模、peer-centric memory | 适合高度个性化助手 | 仅适合明确授权的低风险个性化场景 |
| Vector DB / Hybrid Search | semantic + keyword retrieval | 适合个人知识库 | 企业 RAG 基础设施,但不是完整可信记忆 |
个人智能体应该怎么设计记忆
个人智能体的目标
个人智能体的记忆目标是:
个性化
连续性
可编辑
低成本
隐私可控个人场景中,很多偏好类、习惯类、风格类信息的权威来源就是用户本人。用户说“我喜欢简洁回答”、“我的博客在这个目录”,Agent 可以直接记下来;如果记错了,用户可以纠正。
但个人场景里也有一些事实最好来自外部工具或文件系统,比如日历时间、邮件内容、文件路径、订单状态、代码仓库状态等。因此,个人 Agent 可以接受一定程度的自动记忆,但也需要让用户能查看、修改、删除。
推荐架构
个人智能体可以采用下面的记忆架构:
短期记忆:
Session history / checkpoint / compaction
长期偏好记忆:
OpenClaw MEMORY.md / Hermes USER.md / Mem0 / OpenMemory
情节记忆:
过去对话日志 + semantic search
可选 Zep / Honcho
项目记忆:
project-scoped memory
AGENTS.md / skills / runbooks
用户控制:
查看、编辑、删除、禁用、临时聊天下面是三种典型场景的架构推荐。
推荐组合 A:轻量个人助手
OpenClaw / Hermes
+ Markdown 记忆
+ 会话搜索
+ 用户手动编辑适合日常个人助手。优点是简单、透明、可控。
推荐组合 B:长期个人助手
OpenClaw / Hermes
+ Mem0 / OpenMemory
+ 向量数据库 Milvus / pgvector
+ 用户可查看、编辑、删除适合长期使用的个人 Agent。OpenClaw 的 Markdown memory 很适合个人,因为文件可见、可编辑、可备份;如果加上 Mem0 / OpenMemory,可以获得更好的自动抽取和跨工具检索。
推荐组合 C:项目助手
OpenMemory / Mem0
+ project memory
+ project notes / repo notes
+ AGENTS.md / 项目说明文件
+ skills / runbooks
+ 本地向量库 / pgvector适合围绕项目工作的个人或小团队,例如个人软件项目开发、一人公司的咨询项目、内容项目、客户交付项目等。
它可以记住:
项目目标
项目背景
系统架构
技术栈
测试命令
客户需求
踩过的坑项目助手和普通个人助手不同。普通个人助手主要记住用户偏好和日常上下文;项目助手更强调 项目作用域。同一个人可能同时做多个项目,每个项目的目标、规则、资料和流程都不同。
因此,项目助手需要:
全局用户记忆
+ 项目级记忆
+ 项目资料 / 仓库规则
+ 可复用技能个人智能体为什么可以使用自动记忆
个人记忆通常是:
偏好型:我喜欢什么
习惯型:我通常怎么做
项目型:我正在做什么
上下文型:上次聊到哪里
风格型:我希望你怎么回答这些内容多数是主观的、低风险的,而且用户本人通常就是最终裁判。因此 Hermes、OpenClaw、OpenMemory、Mem0 这类“自动记忆 + 用户可编辑”的方案非常适合个人 Agent。
企业智能体的记忆应该怎么设计
企业智能体的目标
企业 Agent 的记忆目标与个人 Agent 不同:
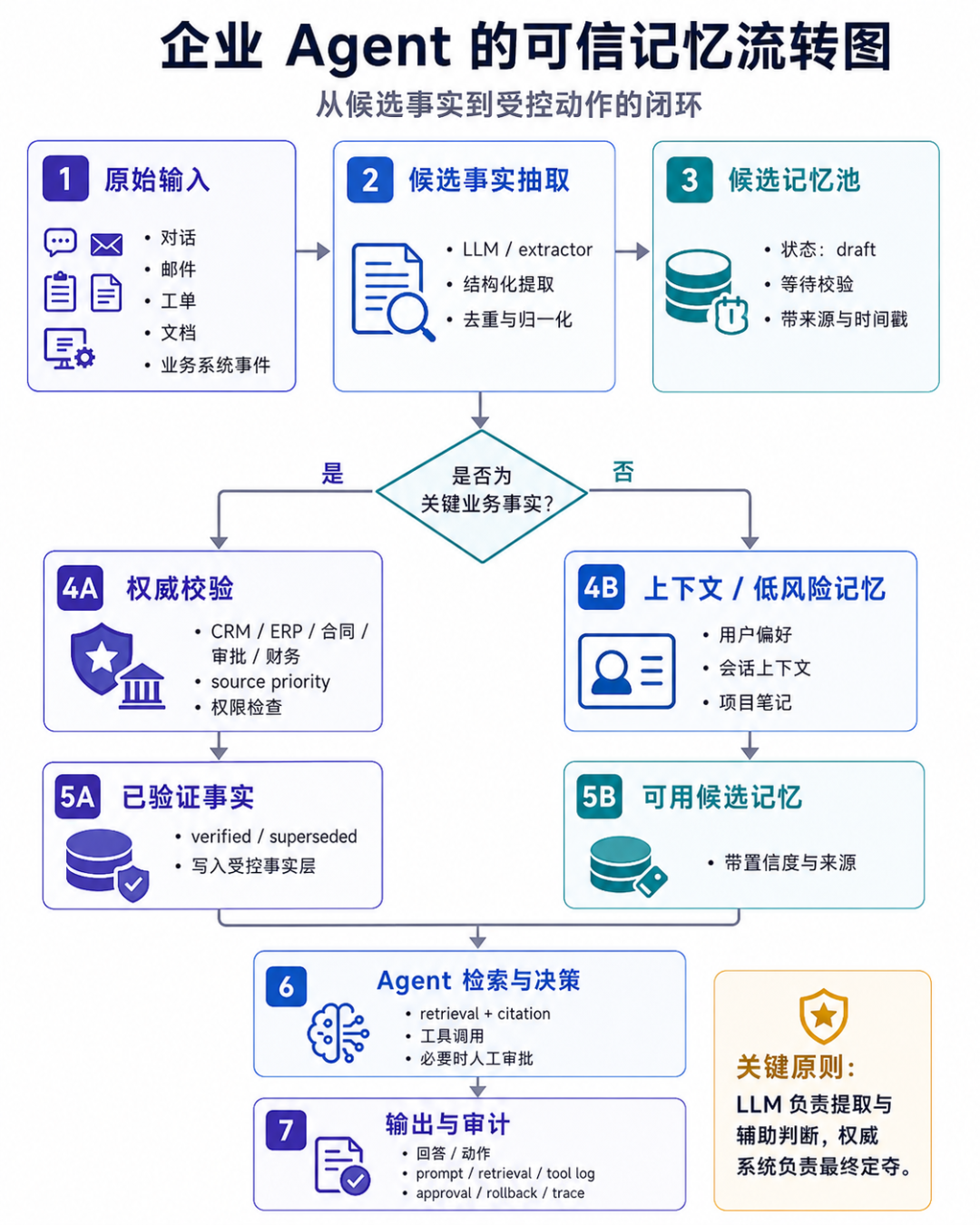
可信性 > 权限 > 溯源 > 时效 > 审计 > 可回滚 > 个性化企业里最大的问题不是 Agent 记不住,而是 它记住了不该记的、错的、过期的、无权限的东西,并把它用于业务动作。
企业记忆的分层
企业 Agent 的记忆应该是多层协同,共同使能,例如下面的分层架构:
L0 会话状态
- 当前任务、当前对话、临时中间结果
- LangGraph checkpoint / OpenAI session / DB session
- 不作为企业事实来源
L1 候选记忆
- 从对话、邮件、工单中抽取的候选事实
- 状态:draft / verified / rejected / superseded
- 可用 Mem0 / LlamaIndex FactExtraction / 自研 extractor
L2 权威事实源 / 系统 of record
- CRM、ERP、HRIS、合同库、订单库、财务系统、审批系统
- agent 只能按权限检索或通过受控 API 写入
- 事实以系统 of record 为准
L3 权威知识与检索记忆
- 政策库、文档库、代码库、会议纪要、知识库
- hybrid search + reranker + citation + ACL
- Weaviate / Qdrant / Milvus / Elasticsearch / Azure AI Search / pgvector
L4 关系 / 时间记忆
- 客户关系、组织关系、项目状态、事实变化
- Zep / Graphiti / Cognee / knowledge graph
L5 程序记忆
- SOP、runbook、skills、审批流程、代码模板
- Git 管理、测试、评审、版本、回滚
L6 审计记忆
- prompt、retrieval、tool call、memory write、approval、output
- 用于追责、评估、合规、复盘这套架构的核心是:LLM 可以产生候选记忆,但不能直接创造企业事实。
推荐组合 A:企业知识问答 / RAG
适合:制度问答、研发文档、合同条款、客服知识库、销售 enablement。
LangGraph / LlamaIndex / Dify-like workflow
+ 企业文档解析
+ ACL 同步
+ Weaviate / Qdrant / Milvus / Elastic / Azure AI Search / pgvector
+ hybrid search
+ reranker
+ citation
+ 审计日志这里的重点不是“长期记住”,而是按权限检索权威知识,并给出来源。
企业文档问答不应该只依赖自动总结记忆,因为合同编号、政策编号、产品型号、客户名、日期等信息需要精确匹配,通常更适合混合检索。
这个组合适合解决:
根据公司政策应该怎么做?
某个合同条款如何解释?
某个系统如何部署?
某个产品功能如何配置?但它不适合直接保存客户状态、审批结果、库存状态、付款状态等动态业务事实。这些应当来自 CRM、ERP、财务系统、订单系统、审批系统等权威事实源。
推荐组合 B:客户 360 / 工单 / 销售上下文
Zep / Graphiti 或 Cognee
+ CRM / 工单 / 合同 / 账单 / 邮件 / 会议纪要
+ temporal facts
+ provenance
+ entity resolution
+ source priority
+ ACLZep / Graphiti 适合这类场景,因为企业事实经常是时变的:客户联系人会变,合同状态会变,项目负责人会变,SLA 会变,问题是否已解决也会变。
Graphiti 的 facts 有 validity window,并能追溯到 episodes;这比普通向量 chunk 更适合回答:
现在是什么情况?
之前是什么情况?
什么时候变的?
这个结论来自哪里?Cognee 则更适合“公司大脑”或跨系统统一记忆,因为它强调 connectors、entity resolution、granular access control、graph + vector search,以及企业 traceability / audit 能力。
需要注意的是,邮件和会议纪要通常更适合作为候选事实或上下文来源;CRM、工单、合同、账单系统才是更高优先级的权威事实源。
这个组合适合回答:
这个客户现在是谁负责?
这个客户最近 90 天有哪些高优先级工单?
这个客户的 SLA 是什么时候变更的?
某个工单关联哪个产品和合同?这类问题只靠普通 RAG 往往不够,因为它们不仅是文档检索问题,也是实体关系、状态变化和时间有效性问题。
推荐组合 C:企业流程执行 Agent
适合:报销、采购、审批、IT 运维、HR 入离职、销售跟进。
LangGraph
+ checkpointer
+ PostgreSQL store
+ policy engine
+ tool call audit
+ human approval
+ 系统 of record API这类 Agent 的“记忆”重点不是记偏好,而是记流程状态:
当前走到哪一步
谁批准了
调用了哪个工具
上次失败原因是什么
是否需要人工确认
是否需要回滚在企业流程里,Mem0 这类自动抽取记忆可以辅助“用户偏好”或“历史交互”,但不能决定审批结果。审批结果必须来自审批系统,付款状态必须来自财务系统,库存必须来自 ERP,客户等级必须来自 CRM。
结语
企业智能体和个人智能体虽然都是智能体,但是记忆要求是不同的。
个人记忆可以自动一点,因为很多偏好、习惯和风格类信息,用户本人就是事实裁判。
企业智能体的记忆要求则是:
每个业务判断都有出处
每个动作都有授权
每条事实都能追溯企业 Agent 的长期记忆主体不应是 Agent 私有记忆,而应是外部化、受控化的组织记忆,包括知识库、业务系统、图谱、流程资产和审计系统。