昨天我在看企业招聘数据,分析企业战略方向是否符合AI时代要求时,看到了一类非常典型的算法岗位 JD。
大概如下:
负责 XGBoost、随机森林、时间序列等算法设计、实现和优化; 负责业务理解、数据预处理、特征工程、模型训练、评估和部署; 将复杂业务规则转化为运筹优化约束; 使用遗传算法、粒子群算法等启发式算法解决寻优问题; 编写技术文档,记录算法方案和优化过程。
如果放在两年前,这是一条很标准、而且相当专业的算法工程师 JD。
它说明企业需要懂机器学习、懂建模、懂业务、懂优化、能落地的人。
但放到今天,尤其是放到模型和智能体能力快速进化的 2026 年,需要给企业提个醒,招聘方向可能错了:
问题不在技术方向,而在工作方式。
这条 JD 是一种典型的“人类专家模式”,因为它将人类作为具体的执行主体。
不否认这种团队内部会在一些具体环节使用AI,但是如果整体目标错了,团队的资源评估和战略配置就会发生方向性偏差。
人来做算法,和管理 Agent 来做算法,需要的组织方式、能力要求、时间金钱成本,是完全不一样的。
这条 JD 里的隐含逻辑是:
我需要一个人,他会 XGBoost、随机森林、时间序列、特征工程、模型训练、模型评估、运筹优化、遗传算法、粒子群算法,并且能把这些东西亲自做出来。
这是传统算法岗位的逻辑:
专家掌握方法; 专家处理数据; 专家设计方案; 专家写代码; 专家调试实验; 专家输出文档。
这套逻辑在过去非常合理,因为之前,算法工程师的个人经验、个人手感、个人代码能力,决定了模型能不能跑起来、效果能不能提升、项目能不能交付。
但今天的问题在于:
XGBoost、随机森林、时间序列、特征工程、模型训练、模型评估这些任务,已经不应该再默认由人类专家亲自完成。
这并不是说算法工程师不重要,但他的价值不应该再主要体现在“亲自写了多少建模代码、调了多少参数、跑了多少实验”。
而应该体现在:
能不能把业务问题定义清楚; 能不能设计合理的评估标准; 能不能让 Agent 生成候选方案; 能不能让 Agent 调用系统自动跑实验; 能不能判断结果是否可信; 能不能识别数据和业务风险; 能不能把一次性经验沉淀成可复用 workflow。
也就是说:
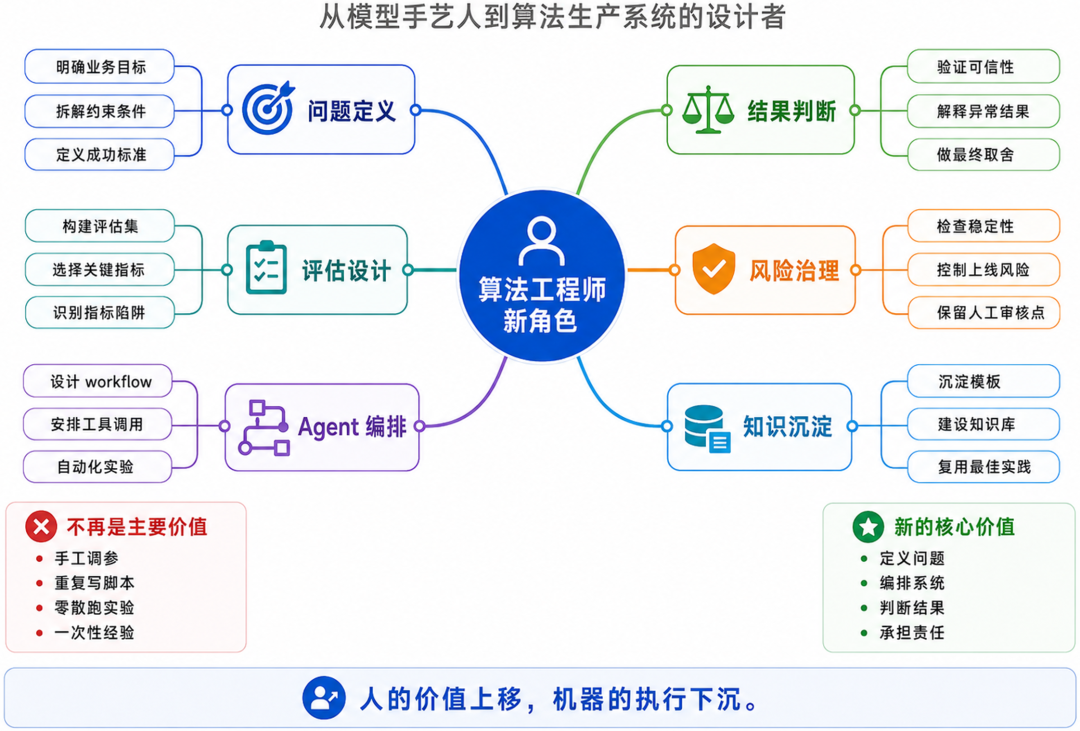
AI 时代的算法工程师,不应该是传统模型手艺人,而应该是算法智能体的指挥者和判断者。
这类有难度的任务,Agent 真的能系统性参与吗?
大模型在各领域的能力是有目共睹的,算法领域也不例外。比如 MLE-bench 用 Kaggle 机器学习竞赛来评估 AI agents 的真实机器学习工程能力,任务包括数据准备、模型训练、实验迭代和提交结果生成,并用 Kaggle 奖牌门槛衡量 agent 是否达到接近人类竞赛选手的水平。
按照 2026 年5月公开主榜结果,Famou-Agent 2.0 在 MLE-bench 上已经达到 64.44% overall medal rate,AIBuildAI 达到 63.11%,CAIR MARS+ 达到 62.67%。这意味着,在一批真实 Kaggle 难度机器学习工程任务中,最强 Agent 已经能在约六成任务上达到奖牌级表现。
这个数据不意味着 AI agent 已经稳定替代所有场景的机器学习工程师。
但它说明了一件事:
机器学习工程已经变成可以被 Agent 系统性参与、评估和改进的任务集合。
此外,大家也都看到了,现在软件行业已经很少有人手写代码了,所以岗位中的软件相关工作也完全应该由 Agent 完成:写数据处理代码、写训练脚本、写评估脚本、写部署接口、写技术文档、调 bug、改 pipeline。
这类 JD 真正落后的地方,是“人做事”的假设
回到这条 JD。
它写的是:
负责 XGBoost、随机森林、时间序列等算法设计、实现和优化;
问题不在 XGBoost,也不在随机森林,更不在时间序列。
这些方法仍然有价值。
问题在于,“设计、实现和优化”这几个词,仍然默认是人亲自完成。
更合理的 AI-native 表达应该是:
负责定义业务建模目标、指标约束和评估标准; 基于 Agent workflow 生成、比较和验证多类机器学习方案; 能够让 Agent 调用 AutoML、训练脚本和实验平台,完成候选模型搜索、性能比较和错误分析; 负责判断模型结果的业务合理性、稳定性、可解释性和上线风险。
再看第二条:
负责业务理解、数据预处理、特征工程、模型训练、评估和部署;
这句话在传统机器学习时代非常标准。
但今天它的问题也很明显:
它把整个模型生产链条都压在“人”身上。
AI 时代,这条链条应该被拆开:

不是人不用懂算法,而是人不应该把主要时间花在重复执行算法流程上。
人应该负责更高阶的事情:
目标定义 约束设定 指标选择 结果解释 风险判断 业务落地 责任承担
这条 JD 应该怎么重写?
符合当前 AI 能力的 JD,应该是招一个“会组织算法生产的人”。
可以这样改:
岗位名称: AI 算法工作流工程师 / 机器学习 Agent 工程师 / 模型系统工程师 岗位职责: 1. 负责将业务问题转化为可被模型和智能体求解的任务定义、约束条件和评估标准; 2. 负责设计和维护机器学习/运筹优化 Agent workflow,包括数据诊断、特征生成、模型候选方案生成、自动实验、结果比较、错误分析和文档沉淀; 3. 能够使用 Agent 调用 AutoML、实验管理平台,加速 XGBoost、随机森林、时间序列、运筹优化和启发式算法方案的生成与验证; 4. 负责建立模型评估集、业务约束检查、人工审核点和上线风险控制机制; 5. 负责将算法方案沉淀为可复用的 workflow、模板、知识库和技术文档。
任职要求也应该改,比如增加:
熟悉 LLM / Agent 在数据分析、代码生成、实验设计和错误分析中的应用; 能设计模型实验的自动化流程,理解 AutoML、实验管理、模型评估和版本追踪; 具备构建评估集、审核规则、异常样本分析和上线风险控制的能力; 能将个人算法经验转化为可复用的 Skill、Prompt、MCP和知识库; 能够判断哪些环节适合交给 Agent,哪些环节必须由人类专家审核。
注意,这不是把算法工程师降级成“只用工具的人”。
这是把算法工程师升级成:
算法生产系统的设计者,Agent 系统的编排者。
其他岗位也是如此
这个问题并不只发生在算法岗,它发生在所有知识工作岗位里。
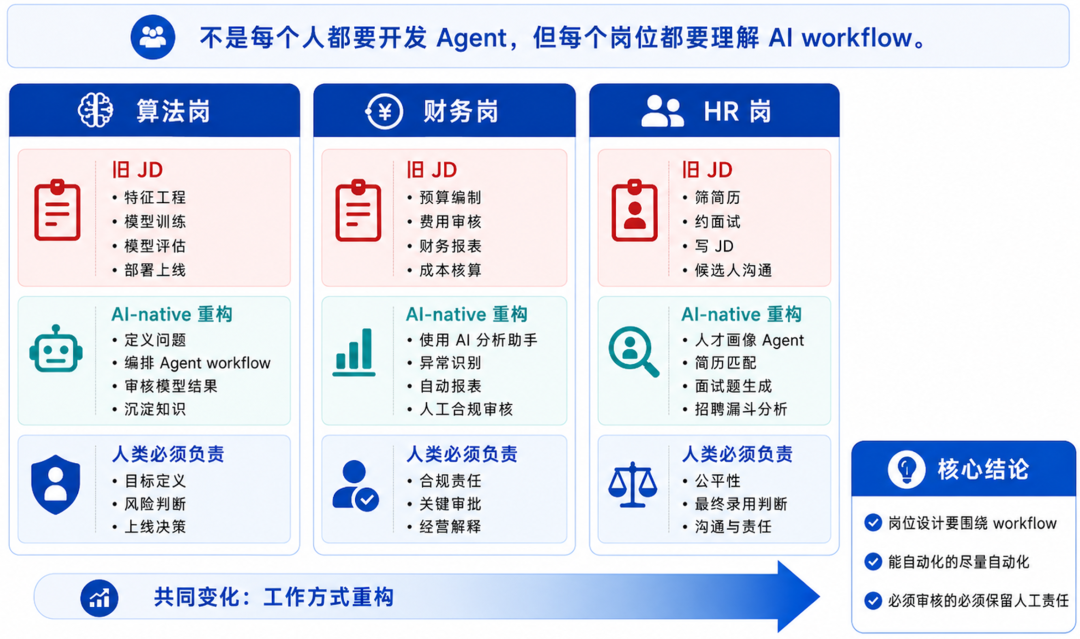
财务类岗位,如果 JD 仍然只写:
预算编制、费用审核、财务报表、经营分析、税务申报、成本核算、凭证整理
但不要求 AI 财务分析助手、自动报表生成、费用异常识别、合同/发票智能审核、预算预测 Agent、经营数据归因分析,那它仍然是前 AI 时代的财务岗。
HR 岗,如果 JD 仍然只写:
筛简历、约面试、写 JD、做候选人沟通
但不要求人才画像 Agent、简历匹配模型、面试问题生成、招聘漏斗分析,那它仍然是前 AI 时代的招聘岗。
注意:对财务、HR 这类非技术岗位,并不是要求每个财务人员、HR 都自己开发 Agent 系统。但他们必须理解哪些工作可以/应该交给 AI workflow,哪些结果需要人工审核,哪些判断必须由人承担责任。系统可以由外部团队或内部技术团队建设,但工作方式必须由任务本身重新定义。
或许有人会觉得,这对非技术岗位要求太高了。但是在 AI 能力快速进化的时代,不能适应这种生产方式的企业,很可能会在效率、成本和响应速度上被迅速拉开差距。
所以,这类 JD 真正的问题不是某个算法岗位落后,问题在于:
企业仍然在用“人类亲自执行任务”的方式,设计已经可以由模型/智能体参与完成的岗位。