MoE 是一种“稀疏激活”的神经网络架构。它将模型中的一部分计算层(通常是前馈网络 FFN 层)替换为一个由多个“专家”子网络组成的集合。对于每一个输入的数据(例如一个词元),一个被称为“路由器”(Router)的机制会智能地选择(激活)一小部分最相关的专家来处理它。这样一来,模型可以拥有海量的总参数,但在处理任何单个数据点时,实际参与计算的参数量却非常小。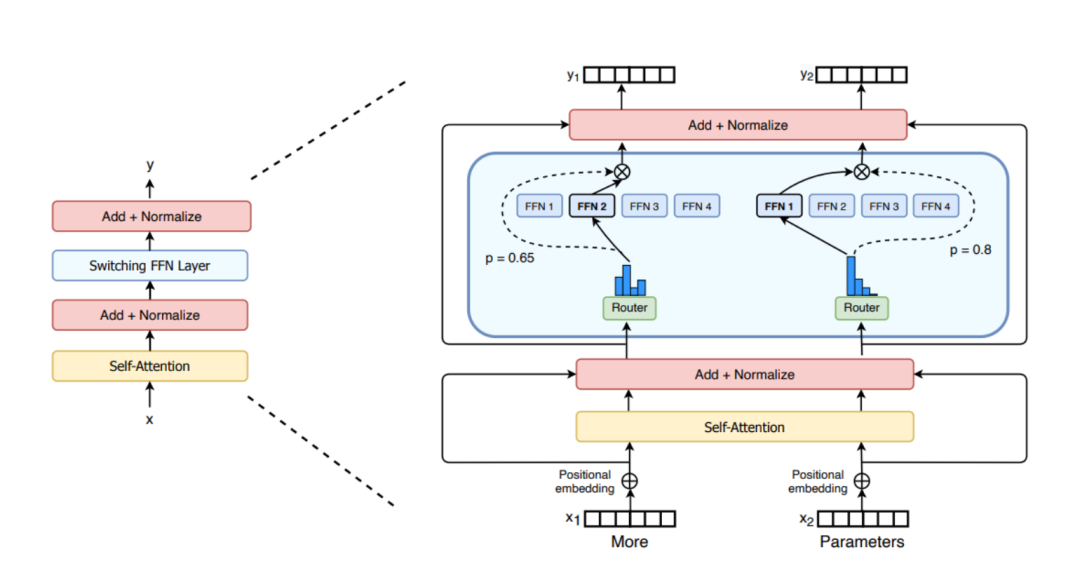
发展的脉络:一部跨越三十年的创新史诗
MoE 的思想并非横空出世,它的演进是一场跨越三十余年的接力跑,充满了智慧的闪光。
1991年:思想的起源。 MoE 的概念最早可以追溯到由 Jacobs、Jordan、Hinton 等人提出的《自适应局部专家混合》论文。 他们设想,与其让一个庞大的神经网络处理所有任务,不如让一组“专家”网络分工,每个专家专注于数据的特定子集。
2017年:现代 MoE 的诞生。 沉寂多年后,来自谷歌大脑的 Noam Shazeer 等人发表了里程碑式的论文《稀疏门控混合专家层》(Sparsely-Gated Mixture-of-Experts Layer)。 他们巧妙地将 MoE 思想融入现代深度学习,特别是 Transformer 架构中,通过引入可训练的“门控网络”(即路由器)来稀疏地激活成百上千个专家中的一小部分。 这项工作真正实现了在计算成本可控的前提下,将模型参数规模提升数千倍的设想。
2020-2021年:走向超大规模的简化与验证。 谷歌的 GShard (2020) 展示了在数千个 TPU 上训练数百亿甚至六千亿参数 MoE 模型的可行性。紧接着,Switch Transformer (2021) 通过采用更激进的“top-1”路由策略(每个token只选择一个专家),极大地简化了 MoE 的设计并提升了训练稳定性,成功将模型参数扩展至万亿级别。 同期的 GLaM 模型则证明,MoE 架构能以显著更低的训练能耗和推理成本,达到与顶尖密集模型(如 GPT-3)相媲美的性能。
2022年至今:产业界爆发与百花齐放。 随着算法的成熟和系统优化的跟进(如 DeepSpeed-MoE 等),MoE 架构迎来了产业化应用的浪潮。从 Mistral AI 的 Mixtral 系列,到 Databricks 的 DBRX,再到 Meta 的 Llama 4、阿里巴巴的 Qwen 系列以及 DeepSeek AI 的 DeepSeek-V3 等,开源和闭源的 MoE 模型层出不穷,MoE 真正从“屠龙之技”变为了业界主流的前沿架构。
当今的主流 MoE 模型
截至当前时间点(2025年8月),MoE 架构已经成为尖端大模型竞争的焦点,以下是一些备受瞩目的代表:
闭源/商用模型:
Google Gemini 系列
谷歌在其官方技术报告中明确指出,其先进的多模态模型采用了稀疏 MoE 架构,以高效扩展模型容量。
- Qwen2.5-Max (阿里巴巴)
一个大规模的 MoE 模型,经过超过20万亿个token的预训练,展示了其强大的性能。
- GPT-4 (OpenAI)
尽管官方未公开架构细节,但业界普遍认为 GPT-4 采用了 MoE 架构,这是其强大能力和高效推理的重要支撑。
开源/开放权重模型:
Llama 4 系列 (Meta)
Meta 的首个采用 MoE 架构的模型系列,例如 Llama 4 Maverick 拥有 4000亿总参数,但每次推理仅激活 170亿参数。
- Mixtral 系列 (Mistral AI)
以 Mixtral 8x7B 和 8x22B 为代表,它们通过每层激活8个专家中的2个,实现了性能和效率的卓越平衡,是开源 MoE 社区的标杆。
- DeepSeek-V3 (DeepSeek)
拥有惊人的 6710亿总参数,但每token仅激活 370亿,并在路由算法上进行了创新,减少了对辅助损失的依赖。
- Qwen3-235B-A22B (阿里巴巴)
总参数量达 2350亿,激活参数量为 220亿,是 Qwen 开源系列中的 MoE 旗舰。
- DBRX (Databricks)
一个拥有 1320亿总参数和 360亿激活参数的细粒度 MoE 模型。
- gpt-oss-120b (OpenAI)
OpenAI 官方开源的 MoE 模型,拥有 1170亿总参数,每token激活 51亿。
MoE 的收益从何而来?
MoE 架构的成功并非偶然,其优势根植于几个深刻的原理。
条件计算:打破“规模-成本”的诅咒。 这是 MoE 最核心的魔力。传统“密集”模型,参数量越大,计算量(FLOPs)就越大。而 MoE 通过稀疏激活,成功地将模型总容量(总参数量)与单次计算成本(激活参数量)解耦。这意味着我们可以构建一个知识储备极其丰富的“巨无霸”模型,但在回答每一个问题时,只唤醒一小部分最相关的专家来思考和回答。其直接收益是:在同等计算预算下,MoE 模型可以比密集模型拥有更大的容量,从而获得更好的性能。
专家专门化:让专业的人做专业的事。 在训练过程中,路由器会逐渐学会将不同类型的数据“分发”给不同的专家。例如,一些专家可能专门处理编程代码,另一些则可能精通诗歌或法律文书。 这种自发形成的分工带来了两大好处:
- 提升性能:
每个专家可以在其擅长的领域内进行深度优化,从而提升模型在多样化任务上的综合表现。
- 更强的泛化能力:
对于一些罕见或长尾的知识,模型可以通过专门的专家来“记忆”和处理,而不会干扰到其他专家的通用能力。
训练与推理效率:更快、更省。 由于每次前向传播只计算一小部分参数,MoE 模型在达到与同等质量的密集模型相同的性能水平时,通常需要更少的训练计算量和更短的训练时间。 在推理(部署)阶段,这种效率优势同样显著,可以实现更低的延迟和更高的吞吐量,这对于实际应用至关重要。
训练与部署:机遇与挑战并存
驾驭 MoE 这匹“千里马”需要独特的“骑术”。无论是在训练还是部署阶段,它都有着与密集模型截然不同的特点。
训练特点
负载均衡是关键: 训练 MoE 的核心挑战之一是防止“专家过载”。如果路由器总是将大部分token发送给少数几个“明星专家”,会导致这些专家过度训练,而其他专家则被闲置,最终损害模型性能。为此,研究者们设计了负载均衡损失函数(Load Balancing Loss),作为一种“惩罚”机制,鼓励路由器将token更均匀地分配给所有专家。
独特的并行策略: 训练超大规模 MoE 模型需要一种特殊的并行技术——专家并行(Expert Parallelism)。在这种模式下,模型的不同专家被放置在不同的计算设备(如 GPU)上。当数据在网络中流动时,需要在不同设备之间进行一次高效的“数据洗牌”(All-to-All Communication),以确保每个token都能被发送到它被分配的专家那里。这极大地考验了计算集群的网络通信能力。
对系统优化要求高: 高效的训练离不开深度优化的软件库,如微软的 DeepSpeed-MoE 和 Tutel,它们专门为解决 MoE 的通信瓶颈和内存管理问题而设计。
部署与推理特点
- 显存的“悖论”:全部加载,部分激活。 这是理解 MoE 部署最关键、也最容易被误解的一点。尽管在进行一次推理时,只有一小部分专家(例如,一个拥有 1410亿参数的 Mixtral 8x22B 模型,激活参数约 390亿)被激活,但在模型加载阶段,必须将所有专家的全部参数都完整地加载到显存(VRAM)中。注:使用Offloading会将推理速度变得非常慢。
这意味着 MoE 模型的显存占用是由其“总参数量”决定的,而不是“激活参数量”。 这也是为什么部署一个拥有数千亿甚至上万亿总参数的 MoE 模型,需要极其庞大的显存资源,通常需要多张高端 GPU 甚至多台服务器协同工作。
通信开销: 与训练时类似,推理时如果模型分布在多个 GPU 上,token在路由器和专家之间的穿梭同样会带来通信开销,这会影响最终的响应速度。
复杂的 KV 缓存管理: MoE 主要稀疏化了 FFN 层,但注意力机制的 KV 缓存依然是密集的。在处理长序列输入时,KV 缓存的显存占用仍然是一个巨大的挑战。
推理优化: 为了让 MoE 模型能够高效地提供服务,业界开发了诸多优化技术。NVIDIA 的 TensorRT-LLM 和 vLLM 等推理框架提供了针对 MoE 的专门支持,包括高效的专家并行、量化(如使用 INT8/FP8 降低显存和加速计算)以及智能的批处理(In-flight Batching)策略,以最大化硬件利用率和吞吐量。
何时选择 MoE?
MoE 架构无疑是当前大模型领域最激动人心的前沿方向之一,它为我们打破性能与成本的“不可能三角”提供了有力的武器。
- 选择 MoE 的时机:
当你需要追求极致的模型容量和性能,尤其是在处理多语言、多领域等复杂综合性任务时,并且拥有强大的分布式计算资源和高带宽网络环境,MoE 是你的不二之选。
- 坚持密集模型的理由:
如果你的应用场景相对简单,模型规模较小,或者计算资源有限(尤其是显存和多节点通信能力),那么传统的密集模型可能是一个更简单、更具成本效益的选择。